

ECS×Fargateのオートスケールをチューニングしてサービス運営費を削減した話
コネヒト
2022-04-20 08:43:39
こんにちは。インフラエンジニアの永井(shnagai)です。
今回は、ECS×Fargateで運用しているサービスの「ターゲット追跡ServiceAutoScalling」をチューニングをしたことで、費用が約半分になるという大きな成果を残すことが出来たのでその内容を経緯と共にまとめています。
内容はざっくり下記3点です。
なぜオートスケールのチューニングをしたのか? 「ターゲット追跡ServiceAutoScalling」のチューニング方法 どんな結果になったか? なぜオートスケールのチューニングをしたのか? コネヒトではWebのアーキテクチャはほとんどECS×Fargateの基盤で動かしています。そして、オートスケールとして「ターゲット追跡ServiceAutoScalling」を使うことで、Fargateのメリットを最大限活かす形で運用コスト低くサービス運用を実現しています。
ここらの話は下記のスライドやブログに詳しく書いているので興味がある方はご覧ください。
ECS×Fargateで実現する運用コストほぼ0なコンテナ運用の仕組み/ ecs fargate low cost operation
speakerdeck.com
ECS×Fargate ターゲット追跡ServiceAutoScallingを使ったスパイク対策と費用削減 - コネヒト開発者ブログ
tech.connehito.com
これまで約1.5年ほど初期に設定したオートスケールのしきい値で問題なくサービス運用出来ていたのですが、ある時を境にレイテンシ悪化のアラートが頻発するようになりました。
よくわからないレイテンシ悪化だったので、アプリケーション側やインフラ側のレイテンシ悪化前後での変更、そしてアクセス特性の分析といった調査をして原因切り分けを行っていきました。
その中で、現状のオートスケールのしきい値 (CPU使用率を30%程に収束させるような「ターゲット追跡ServiceAutoScalling」の設定)では、特定コンテナのLoadAverage(LA)が跳ね上がり、そのコンテナの処理が遅くなることで平均レイテンシが上振れしているという事象を突き止めました。
スパイク的なアクセスに今までは耐えられていたのですが事象がしばらく続いてしきい値を調整しても事象は収まらなかったので、 「ターゲット追跡ServiceAutoScalling」1本で行くのは限界と判断し、新たにECSの「ステップスケーリングポリシー」を導入しました。
ECSのステップスケーリングポリシーとは何か? 「ターゲット追跡ServiceAutoScalling」がCPU使用率/メモリ使用率/リクエスト数の3つから追跡するメトリクスと値を選択することで、ECS側でタスク必要数 (起動するコンテナ数)をしきい値に収束するように動的にコントロールしてくれる機能なのに対して、「ステップスケーリングポリシー」は特定のトリガが発生した時に一気にスケールアウトして タスク必要数 を増やすような用途に使えます。
ステップスケーリングポリシー
docs.aws.amazon.com
今回の対応だと、 CPU Utilization Max の値がしきい値を超えたタイミングで、タスクを3つスケールアウトするような設定を入れました。具体の挙動としては、「ステップスケーリングポリシー」を設定すると、裏でCloudWatchAlarmが作られて、そのアラームをトリガーとしてECS側でスケールアウトが走るような仕組みになっています。
これを入れることで、スパイクの初動の段階で一気にスケールアウトが走るようになりレイテンシ悪化のアラームを抑えることに成功しました。
次なる課題 「ステップスケーリングポリシー」を導入したことによってレイテンシアラームは抑えることに成功したのですが、思想的に十分な余裕を持ってリクエストを迎えるための設定になるのでタスクの起動数が上振れ(費用増)するようになりました。「ターゲット追跡ServiceAutoScalling」のしきい値はそのままに、「ステップスケーリングポリシー」でオートスケールを追加したので当然の結果です。
ここからは、「ターゲット追跡ServiceAutoScalling」のチューニングをして、Fargateタスクの平均起動数を下げることで費用削減にチャレンジしました。
「ターゲット追跡ServiceAutoScalling」のチューニング方法 チューニングの方針として、「タスクあたりのリクエスト数(1コンテナが捌くリクエスト数)」を上げるのを目的に、「ターゲット追跡ServiceAutoScalling」でしきい値としているCPUUtilization avgを上げていくアプローチをとりました。
下記のキャプチャは、CloudWatchで見られる RequestCountPerTarget の推移なのですが、短期で見ると振れ幅ありつつも長期トレンドでは徐々に下がっていることがわかります。これが下がるということは、全体のリクエスト数は少しずつ成長しているとした場合に、1タスクあたりのコスト効率が悪化していることを意味します。
「ターゲット追跡ServiceAutoScalling」のチューニング方法としては、下記を繰り返して最適値を探りました。
しきい値とするCPUUtilization avgの値を1%インクリメント 2日間問題が起きないかという様子を見る ガードレールメトリクスとして、アラートならずともレイテンシ悪化がゆるやかに起きていないかをチェックする 問題なければ1に戻る。該当期間にアラートが出たらしきい値を元に戻して2の様子見期間へ。 この繰り返しで1ヶ月程かけて最適値を探りました。チューニング方針が慎重すぎないか?という感想をもしかしたらもたれるかもしれません。
ただ、本番運用サービスでチューニングを行うので出来るだけリスクを抑えたいという判断から時間はかかりますが、1%ずつの調整を行うことにしました。
また、しきい値調整のオペレーション自体は軽く、監視も基本的にはアラートがならない限りはアクションしないという方針で取り組んだので、長い時間をかけることが出来たというのも正直なところです。
モニタリングには、CloudWatchを使ってモニタを作り、チューニングが与える変化をウォッチしていました。
下記の4項目を一つのモニタにまとめています。
ALBのReqCount(該当サービスのリクエスト数) ECS CPUUtilization avg(該当ECSサービスのCPU使用率 平均) ECS CPUUtilization max(該当ECSサービスのCPU使用率 最大) ECS RunningTaskCount(該当ECSサービスで起動しているタスク数) 例えば、このモニタからこんなことが読み解けるような作りになっています。
ALBのReqCountが急激に上がった時に、ECS CPUUtilization maxがしきい値を超えてECS RunningTaskCountが3タスクスケールアウトしており、ECS CPUUtilization avgはしきい値前後で収束している 夜間でALBのReqCountが落ちてくると、ECS CPUUtilization avgが収束し、RunningTaskCountが最小値の値までスケールインした また、CloudWatchは水平/垂直の注釈を入れれるので設定変更のタイミングやしきい値に注釈を入れることでグラフを見ただけで読み取れる情報が格段に増えます。この機能は便利だなと思っています。
どんな結果になったか? チューニングは、アラートが鳴るギリギリのところまでレイテンシが悪化する状況が見えてきたところで一旦インクリメントは終わりとして、しきい値から少しゆるめた落ち着いたところでFixさせました。
結果として目標においていた、以前の水準まで「タスクあたりのリクエスト数(1コンテナが捌くリクエスト数)」を上げることに成功しました。また、それに応じてSavingsPlansで購入する Compute Savings Plans を半分ほどに削減することが出来、システム運営費の削減に成功しました。
※この半年後のSavingsPlansの切れるタイミングで、測定したところ従来の半分くらいの購入で良いことが判明した
最後に宣伝です! コネヒトでは一緒に成長中のサービスを支えるために働く仲間を様々な職種で探しています。 少しでも興味もたれた方は、是非気軽にオンラインでカジュアルにお話出来るとうれしいです。
コネヒト株式会社
hrmos.co

コネヒトはPHPerKaigi 2022にゴールドスポンサーとして協賛します!
コネヒト
2022-04-06 08:52:18
こんにちは!@otukutun です。今回は弊社が協賛し、弊社社員が登壇するイベントを紹介します。
PHPerKaigi 2022に協賛いたします コネヒトではメインプロダクトである「ママリ」を始めとして開発のメイン言語としてPHPを活用しており、フレームワークとしてはCakePHPを採用しています(その他、技術スタックを知りたい場合はこちらをご覧ください)
その縁もあり、この度 PHPerKaigi 2022 にゴールドスポンサーとして協賛させていただくこととなりました!
イベント概要 日時 2022年4月9日(土)〜4月11日(月) 場所 練馬区立区民・産業プラザ Coconeriホール および ニコニコ生放送 主催 PHPerKaigi 2022 実行委員会 公式HP https://phperkaigi.jp/2022/ タイムテーブル https://fortee.jp/phperkaigi-2022/timetable 公式サイトからの引用になりますが、PHPerKaigiは
PHPerKaigi(ペチパーカイギ)は、PHPer、つまり、現在PHPを使用している方、過去にPHPを使用していた方、これからPHPを使いたいと思っている方、そしてPHPが大好きな方たちが、技術的なノウハウとPHP愛を共有するためのイベントです。 今年はPHPerKaigi初のオフラインとオンラインのハイブリッド開催です。
となっており、いろんな方が楽しめる間口の広いPHPのイベントになっていそうです!今回ははじめてのハイブリッド開催なので、都合がつく方は両方で参加して楽しむこともできそうですね!
発表内容やタイムスケジュールを知りたい方はこちらをご覧ください!
タイムテーブル | PHPerKaigi 2022 #phperkaigi - fortee.jp
また、最新情報はTwitterで告知されるので PHPerKaigi 公式Twitterも要チェックです!
@phperkaigi
コネヒトからの登壇者の紹介 弊社からは@takoba_ が登壇します。
2022/04/11 12:10〜 Track B レギュラートーク(20分)
CakePHP Fixture Factories の登場によって変化する、PHPプロジェクトにおけるテストフィクスチャ管理の選択肢
fortee.jp
CakePHPでテストデータ動的な生成方法について説明がありそうなので個人的にもすごく興味あります。
チケット購入 こちらからチケット購入できますのでよければぜひ!
www.eventbrite.com
最後に ここまで読んでくださった皆様、ありがとうございました。 そして、 PHPerチャレンジ中の皆様、お目当てのPHPerトークンはこちらです!
#AFTER_TECH_COMPANY
それでは!
コネヒトではPHPerを積極採用中です!
hrmos.co
【永久保存版!】プロジェクトリーダー必見!!チームふりかえりを最高に楽しいものにするたった一つの方法【リモートワーク対応】【2022最新版】
コネヒト
2022-04-05 02:59:57
こんにちは ohayoukenchan です! 4月と言えば新生活。コネヒト株式会社も4月から、経営体制を一新し新たなスタートを切りました。 今期も心機一転して頑張っていきたいと思います。
この記事では先月末に開催した下期(6ヶ月)のチームふりかえりで行ってとても良かったなと思ったことについてお伝えできればと思います。
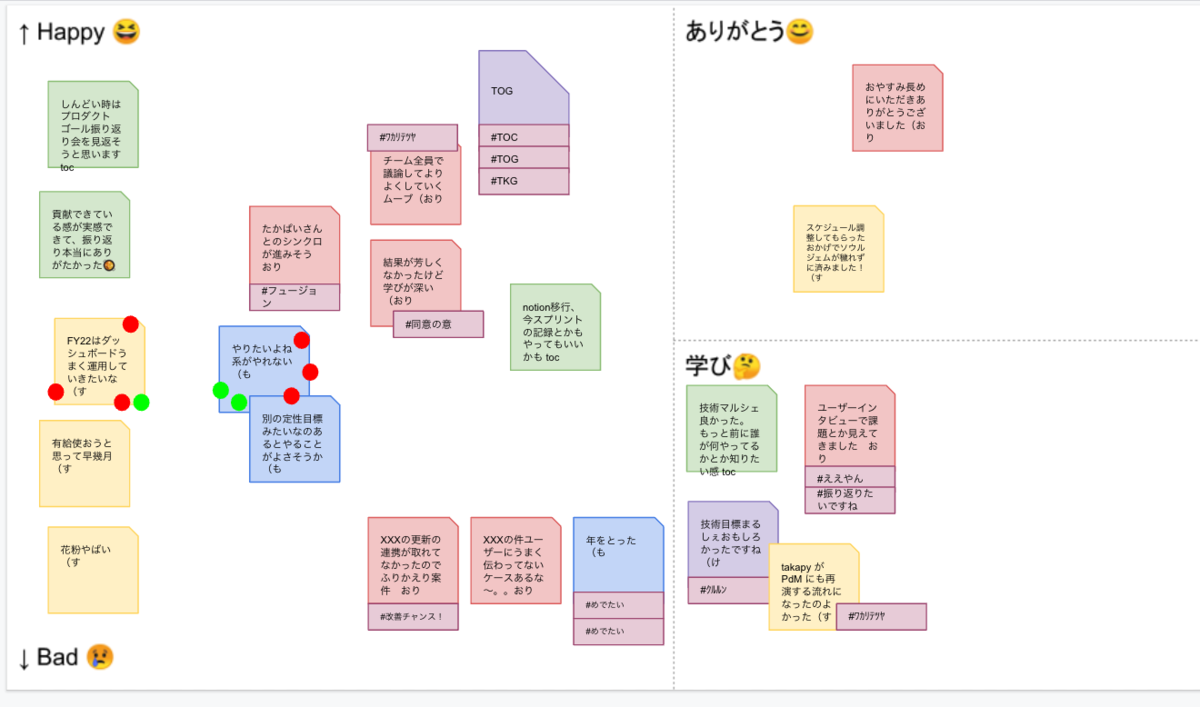
中長期(数ヶ月間隔)のふりかえり会の意義 スプリントでのふりかえりは、スプリントごとにレトロスペクティブの時間を設けています。 KPT法に似たような方法ですが、例えば下図のような感じでチームで起こったできごとに「ありがとう」や「happy-bad」と書かれた領域に付箋を貼って、特に関心の高いものに対して次のスプリントへのtryを決めていきます。
スプリントごとのふりかえり
また、弊社の別のチームでも、Win Sessionで元気に目標を達成するチームづくりの記事にあるように、チームが元気な状態で目標を達成できるように、来週も頑張るぞと思えるような取り組みを行っています。
では、中長期(数ヶ月間隔)のふりかえりはどのように行えばよいでしょう? 今回開催した下期ふりかえりも、チームが元気な状態で来期に向けて頑張る気持ちを醸成したいと思い企画しました。
ふりかえり会の内容 ふりかえり会を企画した時に注目したキーワードは「自己肯定感」です。
ふりかえりが終わった後に、自己肯定感が満ち溢れているメンバーの顔を想像しながらアジェンダをつくりました。
自己肯定感が高ければ、自分に自信を持つことができ、何事にも積極的に取り組んでいけると思いました。逆に自己肯定感が低いまま次のスタートを切ることになると自信が持てず、仕事を置きに行くことになりがちです。仕事を置きにいくようになってしまうと目標がゴールになり、それ以上の成果は望めません。
それでは、自己肯定感をあげるにはどうすれば良いでしょう? 一番確実でほとんどのメンバーが喜ぶのは「評価される = 褒められること」だと思います。
チームメンバーを一人残らず褒めちぎるにはどうすればよいか考えた方法がこちら。(下記画像)
メンバ一人ひとりにおてがみを書いてもらう
そうです。メンバーひとりずつ他のメンバーに対してお手紙を書いてもらうだけです。 半年間通して一番近くで仕事をしてきたメンバーからみた印象を書いてもらいます。それを当日読むだけです。
当人が努力したことでも、誰からも評価されなければ無価値、無意味などの消極的な思考が脳内を支配してしまいがちですが、チームのメンバーは見ていた、努力していたことを知ってるはずです。 AさんがBさんをねぎらうだけでBさんは救われた気持ちになって、BさんもまたCさんを救うのです。最高です。
これが私がチームメンバーからもらったお手紙です。
私はこの半期、さまざまな駄作なアイデアや、良かったと思ってもらえるアイデアを出してきましたが、ここでアイデアマンという評価をもらえたのは嬉しかった。アイデアも不作が続くと自信がなくなってくるので「もっと出していこう!」「いいんだ。アイデア出して!と思える最高な💌でした。また、子育て中ということもあり、チームの行事に参加できなかったりしていた後ろめたい気持ちも完全に取り払ってくれました。ありがとう!
似たようなものに360°フィードバックがあります。360°フィードバックは評価者からみて被評価者の評価を決定するためのシステムとしては良いですが、どうしてもフィードバックする側は評価されるべき功績をフィードバックするので、今回の目的である自己肯定感をあげることには繋がりにくいかなと思います。
ふりかえり会で準備したこと 準備するのはお手紙にするテンプレートを一枚用意するだけです。
他の人からテンプレートを閲覧できないように注意しつつ、後は趣旨をDMなどで伝えます。
これをメンバー分繰り返して、書いてもらっていない人がいなければ完了です😊
あるといいもの 今回は、チーム個人の自己肯定感をあげることの他に「チームで頑張って良かった。また頑張ろう」という気持ちも醸成したかったのでチーム外からのフィードバックも集めることにしました。
メンターだった先輩からの💌 CSチームからの💌 CTOからのはげましの💌 社を去ることになった前代表からの💌 基本的にはチーム外からみたチームの印象を書いてくださったのですが、今回の大きな気づきとして、他の人にお願いする方が自分が想定していたものより素晴らしいものが出来たということでした。
例えば、CSチームのメンバーとの取り組みからお手紙をもらおうと自分は青写真を描いていたのですが、CSチームからもらったお手紙には自分たちのチームがこれまで改善したことにたいする「ユーザーからのフィードバック」を添えてくれていました。このことは全く想定していなかったし、結果想定した以上にチーム内からの反響も大きかったです。
想定の範囲内という言葉がありますが、想定の範囲内で物事を動かしてはもったいないです。自分ですべてやるより周囲の人を巻き込んでいくと良いと思います。
定量は測れませんが、定性的には良い会だったであろうことを感じていただけると思います😋
最後にひとこと 自己肯定感をあげる方法は他にもあると思うので、必ずしもこの通りやる必要はないと思いますし、所属するチームの状況によって最適な手段を選んでいくのが大事かなと思います。 大事なのはチームメンバーを一人残さず褒め讃えて、自己肯定感が高い状態で次の期へ突入することです。 あと、内容は作り込み過ぎずブレスト段階でどんどん協力者に移譲していきましょう。
今回の記事はプロダクトゴールのふりかえりについてでした。弊社のプロダクトゴールの運用についてはこちらの記事が参考になりますので、是非のぞいてみてください
tech.connehito.com
4月から新しい期が始まり、ロケットスタートで階段を駆け上がっていくイメージの弊チームですが、まだまだやりたいことがたくさんあり、全然手が回っていません!
バックオフィス、UIデザイナー、エンジニア、PMMなど多業種でご応募お待ちしておりますので、 ohayoukenchanにDMでお声がけください。
下記募集一覧からご応募もできます。
hrmos.co
よいチームを作っていこうず!

コネヒトの文化が生み出すスキルアップを支える社内LTイベント
コネヒト
2022-03-30 01:00:00
こんにちは。2017年11月にAndroidエンジニアとしてjoinした@katsutomuです。
前回のエントリーで、髪の毛のアップデート予定について触れましたが、重い腰を上げて予定を決めました。4/3を予定しています。
さて今回は、先日社内で実施したLTイベントの技術目標マルシェについて紹介します。
はじめに まずは今回の社内イベントについて補足させてください。
シンプルにいうと、スキルアップ目標の工夫をシェアして、お互いに刺激を受けるイベントです。
マルシェ is 何?
社内で実施しているLTイベントのコネヒトマルシェのコンセプトでもあるみんなの「知りたい」「知ってる」をおすそ分け!をテーマに、技術目標でやったことをアウトプットできる場、そして、みんなが和気あいあいと交流出来る場を目指しています。
技術目標 is 何?
エンジニア組織に所属するメンバーが半期ごとに持つ、個人のスキル成長を促す技術的な目標です。直接会社に貢献するものでなくてもOK(全く関係ないものはNG)ですが、計画的にスキルを伸ばすことを念頭に置き、期初に成果指標を置いています。 今回のイベントは、技術目標に関連したアウトプットを行うことで、コミュニケーションが生まれて、仲間からのいい刺激を貰い、また自分も渡せる場として、期末に実施をしています。
イベントの内容 開発組織に所属しているほぼ全員(18名)がそれぞれ学んだことを発表しました。ランチタイムも含んで、合計5時間のイベントになりました。タイムテーブルは以下の通りです。
タイムテーブル
時間 内容 12:00 ~ 13:00 はじまりのお話 + LT × 4 13:00 ~ 14:00 ランチタイム 14:00 ~ 15:20 LT × 7 + 10分休憩 15:40 ~ 17:00 LT × 8 + 10分休憩 17:00前後 おわりのお話 一人あたり5~10分のLT枠を好きに使ってもらい、10分オーバーした場合は、インターセプトして終了する予定でしたが、進行していく中で、余白の時間が生まれてきたため、ゆっくりと進行することができました。発表一覧は以下の通りです。
発表一覧
タイトル キーワード ポートフォリオを作ったぞい Vercel / React / Next.js / CSS Module / Every Layout テストとかLTとか React / Jest / testing-library LT: FastAPI 家族ノートのフロントエンドを改善してるぞい React / Jest / CakePHP Graph Embeddingを用いたタグのベクトル表現分析 python / データ分析 / node2vec 洋書で読んでまとめるぞい 洋書 / オブジェクト指向設計 AWSの認定資格 AWS / 認定資格 / クラウドプラクティショナー 技術目標で作ったサービス紹介 Next.js / TypeScript / Tailwind CSS / Jest / MSW(Mock Service Worker) CakePHPerのためのLaravel教養講座 PHP / Laravel Deno入門 Deno / Deno Deploy 問いかけのススメ マネジメント / コーチング 100年ぶりの Go Go / Android くるるん検査器を作ったりくるるんを動かす iOS / ML 知ってるようで知らないサジェストの裏側の世界 Elasticsearch FY21下期のアウトプット駆動で得た知見たちをおしゃべりする 書籍執筆 / Python Goワカラナイ しくじり先生編 Go フレームワークを写経した感想 PHP / フレームワーク #phperkaigi2022のスライド作成RTA PHP / テストフィクスチャ SwiftConcurrencyダイジェスト版 iOS / Swift Concurrency それぞれがさまざまなジャンルを学んでいたため、バラエティに富んだ内容となりました。自分の業務領域を深めるメンバーもいれば、普段の領域から離れたことを学んでいるメンバーもいました。
工夫したこと イベントを開催する上でに、主に3つの工夫を凝らしました。
発表のハードルを下げる 有志とイベントを作る 次につながる仕掛けをする 発表のハードルをさげる 評価の場でないことを伝えたり、スライドに落とす以外のLT方法もウェルカムとしたり、進捗に不安がある場合に1on1の活用やもくもく会を活用することを事前にアナウンスしていました。
技術目標マルシェは「正式な評価の場」というわけではないのでどんな内容でも、それが原因で評価が下がることはありません。 あくまで前述した通り「アウトプットの場」、「相互コミュニケーションによる技術目標の推進」を目的としています! - 発表フォーマットはなんでもOK! - スライドで発表、成果物のデモ、フリートーク、投稿したブログの紹介、工夫したことetc - 毎月のテーマ & 振り返りを活用しましょう - まずは自分が納得できる状態を目指して欲しいです。 - その上で誰かと壁打ちできると良いと思うので、気軽に相談していきましょう - 技術目標もくもく会を活用しましょう - 下期も有志メンバーがもくもく会を実施してます。 - 「技術目標をやる時間がありません」というお悩みもあると思うので、是非活用してみてください 和気あいあいとした雰囲気で刺激を与えあうためには、自分が納得することと、やりやすい方法で発表することを、大事にしてほしいと考えていました。結果的にはスライドを作るメンバーが多かったと思いますが、それぞれが工夫をこらしていたので、長時間のイベントでも集中力を切らさず、聞けた感覚がありました。
有志とイベントを作る イベント当日を、よりよい時間にするためには、わたしだけのアイディアでは、不十分だと感じていました。開発組織のメンバーが揃うミーティングで、有志メンバーを募り、委員会を結成しました。
わたしが決めかねていると、色々なアイディアを出してくれたり、意見を伝えてくれたり、タスクを率先して拾ってくれたため、スムーズに進めることができました。
せっかくなので委員会のミーティングでの議事メモを公開しておきます。
- オンライン?オフライン? - コロナの見通しが立ってないので、オンライン。 - 技術目標マルシェはどういう位置付け?福利厚生というかみんなでワイワイ楽しむ時間と割り切っていいものなのか、いや20人をN時間拘束するから仕事としてちゃんとやってくれ、なのか - LT大会はビール飲みながら聞きたいですね〜 - 人数多くて、時間配分がむずい - 20人分だと長いし、時間をオーバーする人もいるかも - 直感的にはドラというか時間でちゃんと切るのが必要だと思う、iOSDCのLTみたいな感じ - まさにiOSDCをイメージしてた - 画面共有奪っちゃうとか(いらすとや表示するなど - お昼を挟むタイムラインにするとか? - 朝早く働いている人もいるので、時間ずらしちゃった方が良い? - ボックスMTGその日無くす(ずらす)とかもありかも - 話さなきゃいけないことはランチの前後に話してもらうとか - 組織編成の話とかが出てきた場合、心が休憩できるか? - フィードバックはどう送ろうかな? - コール&レスポンスを含めると、Zoomのチャットで全部やった方が、盛り上がり感はあるかも - がやはZoom、フィードバックはシートだと移動が面倒。 - まっさらなところに付箋を書くと心理的に書きづらい - 運営が後から、notionなどにフィードバック一覧を作るとか。 - zoomのチャットだと流れるのが懸念だったが、後からまとめるのであれば良いかも - その方法でいくならば区切りをちゃんとしたほうがいいと思うので、運営からチャット欄に「◯◯さんLT開始、終了」みたいなのを書くとかかな - Slackでいいかも? - Ask the speaker的なのあるといいですけどね - 感覚的にはこの規模なら全員が全員の発表を聞いたほうがいいと思っているので、時間の制限を考えると、この日は聞くことに専念して、後日別の場(Web Talkなど)で話題に出すのはどうだろう? 次につながる仕掛けをする 多くのエンジニアにとってスキルをアップデートしていくことは、継続的に行うことが大事だと思います。今回のイベントの熱量を次に生かすために、定期的な社内サブイベントで参照しやすいように発表一覧にタグをつけてみました。
画像の一覧はWebエンジニアが、集まるイベント用のタグです。わたしはAndroidエンジニアなので、普段は参加していないですが、次回のイベントで改めて話題に出して、相互に感想を話すことを提案する予定です。
以上のように、3つの工夫を紹介しましたが、どの工夫にも根幹には、アウトプットできる場を用意し、みんなが和気あいあいと交流出来る状態を作り出すことを意識していました。
その後.... これはわたしが意図したことでは、全くないですが、発表したことを社内にシェアして、次のアクションにつなげているメンバーがいました。
おそらく、今回のイベントがなくても同じ行動をとってくれていたとは思いつつもイベントを実施したことで、新たな変化が生まれたようで、イベントを実施した甲斐があったと感じました。
感謝!
おわりに さて、今回は、開発組織で実施したLTイベントについて紹介させていただきました。
イベント開催にあたり、できる限りの工夫は凝らしましたが、コネヒトに元から備わっている、アウトプットを真摯に受け止めたり、わきあいあいと技術を楽しむ文化がベースにあることで、想定していたよりも、いい時間を作れたと思っています。
内容について、カジュアル面談で補足できますので気軽にお声掛けください!
hrmos.co
SwiftUIでUIを宣言的にかけるようになりコードを書くのが楽しいぞい
コネヒト
2022-03-29 01:58:22
こんにちは、ohayoukenchanです。
今回はSwiftUIについてです。 ママリではiOS13をサポートしているので、一部iOS13をサポートする内容が含まれます。
システムを長持ちさせる力 突然ですが、コネヒトのエンジニアリング組織はTech Visionというものを掲げており、概要としては「みんなでエンジニア組織強くしていこうず。」的なことが書いてあるんですが、そのなかの3つの技術力として「システムを長持ちさせる力」を重要な技術力として推進しています。
ママリiOSアプリでも最新技術の恩恵を受け続けられるよう日々コードのアップデートを行っております。
先日、弊社ではTech Vision推進の一環で、技術目標マルシェなるものが開催されました。詳細はこちらのポストをぜひ覗いてみてください!
tech.connehito.com
技術目標マルシェは社内イベントで、各自比較的自由に気になる技術を選んで発表するのですが、自分はCoreMLとVisionを使って画像分類したり、エッジ抽出した画像をSKTextureにしてSpriteKitで遊ぶという内容を発表しました。
iOS版のママリも、直近まではStoryboardやUIViewを使った開発をしていました。
Storyboardを使った開発の場合、UIの基底となるStoryboardでは実装内容はわかりません。ここからUIKitを使って実装を付け加えていくのですがUIを組み立てるのに、UITableViewCellやUIViewを継承したファイルを増やしていくことになります。
なにが行われるかわからないstoryboardの例
Storyboardを使った開発がレガシーとは言い切れませんが、昨今、reactを筆頭に、宣言的UIで書かれたコードの見通しの良さ、逆にUIKit(storyboard)でUIを組み立てていくコードの見通しの悪さを考えると、サポートバージョンを考慮しつつ、これから開発するシステムに関してはSwiftUIを使って開発していこうという結論になりました。
アーキテクチャについて SwiftUIと相性の良いライブラリにTCA(The Composable Architecture)があります。状態の集中管理したり、scopeを使うことでwatchするstateの範囲を限定できることで、無駄に再描画が発生しなかったり、テストライブラリも用意されているので非常に魅力的でしたが、TCAの懸念としては、Viewも含めてTCAに強く依存してしまうので、TCAを使わなくなった場合に引きはがずのが大変そうであることが理由でTCAの採用は見送っています。
いままでのiOS開発のライブラリの流行り廃りを考慮すると他によいものがでてきて廃れる可能性もわりと高そうという議論もしました。
余談ですがFluxベースのライブラリの有名どころにreactのreduxがあると思うのですが、reactがhooksを導入したことでreduxなしで状態管理できるようなアプローチをとってきているので状態管理をどの場所で行っていくのか今後が気になっています。
https://github.com/pointfreeco/swift-composable-architecture
ママリiOS版のリアクティブプログラミング構成 ママリiOS版は、MVVMアーキテクチャで構成されており、APIやUIからのイベント送信などにRxSwiftやRxCocoaを使用しています。SwiftUIを導入するにあたり、RxSwiftを切り離し、代わりにCombineを導入することも検討しましたが、RxSwiftへの依存が強いことと、Rxコミュニティは活発でライブラリ更新も積極的に行われていることから、無理に引き離すような選択はしていません。
新規でUIを作成する場合、状況に応じてRxSwiftで流れてきた値をCombimeのPublisherにわたしたりしています。一つのファイルにCancellableとDisposeBag両方書かなくてはいけないなど、コードの見通しが若干悪くなるのですが、これは移行期という捉え方が近いとおもっていて、継続的に運用を続けていくことを視野に考えると、その機能自体なくなるかもしれないし、該当機能に大幅なアップデートがかかるかもしれません。可能性を考慮するときりがないので今は移行期としてこのような仕組みになっています。
fileprivate let disposeBag = DisposeBag() fileprivate var cancellables: [AnyCancellable] = [] Hosting Controllerの取り扱い ママリでは既存のアーキテクチャとの兼ね合いもあり、画面遷移は UIViewControlerに任せることにしました。UIHostingControllerを継承したクラスの rootView に SwiftUIの View を渡すようにしています。 super.init(rootView:) するときにclass内のプロパティを初期化して渡してあげたいけどSuperクラスの初期化が終わってないのにサブクラスのプロパティにアクセスするなと怒られてしまいます。
コンパイルエラーの例
class DiagnosisInterestingTopicsViewController: UIHostingController< DiagnosisInterestingTopicSelectView > { private var cancellables: [AnyCancellable] = [] var viewModel: DiagnosisInterestingTopicsViewModel() init(interstingTopics: InterestingTopicsResponse) { super .init( rootView: DiagnosisInterestingTopicSelectView( viewModel: viewModel // 'self' used in property access 'viewModel' before 'super.init' call ) ) } ・・・ この場合、super.init(rootView:) の前にViewModelを作っておくとコンパイルエラーを回避することが出来ます。rootViewに指定したいViewの引数とClass内部で取り扱うviewModelを一致させるためにこうしてますが、見通しは悪いですね。
コンパイルが成功する例
class DiagnosisInterestingTopicsViewController: UIHostingController< DiagnosisInterestingTopicSelectView > { private var cancellables: [AnyCancellable] = [] var viewModel: DiagnosisInterestingTopicsViewModel! init(interstingTopics: InterestingTopicsResponse) { let viewModel = DiagnosisInterestingTopicsViewModel( interstingTopics: interstingTopics ) super .init( rootView: DiagnosisInterestingTopicSelectView( viewModel: viewModel ) ) self.viewModel = viewModel } ・・・ HostingControllerで既存UIKitの画面を表示する 通信中画面はSVProgressHUDを使用しています。SwiftUIを使った画面でも既存のUIを使用したいので、SwiftUI側でSVProgressHUDを表示すると、SwiftUIの描画領域しかオーバーレイされず、NavigationBarなどがオーバーレイの上に表示されてしまいました。そのため、SVProgressHUDはUIHostingController から呼ぶようにしました。
ママリiOS版はiOS13をサポートしているため、iOS13で検証したところ通信が発生してもオーバーレイが表示されず、検証したところviewDidLoadで処理してもviewModel.$progressState に値が流れず、viewDidAppearで呼ぶことで回避できました。原因は分かってないです。
class DiagnosisRegionSelectViewController: UIHostingController<DiagnosisRegionSelectContainerView>, DiagnosisPageable { ... 初期化処理など省略 override func viewDidAppear(_ animated: Bool) { super.viewDidAppear(animated) // iOS13だとviewDidLoadにおくと呼ばれないのでviewDidAppearで処理 bindUI() } func bindUI() { viewModel.$progressState .receive(on: DispatchQueue.main) .sink { state in self.showProgressView(state) } .store(in: &cancellables) } func showProgressView(_ state: ProgressState) { switch state { case .asleep: SVProgressHUD.dismiss() case .connecting: SVProgressHUD.show(withStatus: "通信中", maskType: .black) } } SwiftUIで宣言的にかける良さ SwiftUI導入のメリットである宣言的UIを実現させたいので、複雑なロジックは持たず、UIの組み立てに集中させています。こちらはSwiftUIで書いた機能ですが1画面を構成するのに50行くらいのSwiftUIファイルを書くだけだったので大変見通しもよく(storyboardもcellもいらないなんて!)
感動しました
struct DiagnosisRegionSelectSearchView: View { @ObservedObject var viewModel: DiagnosisRegionSelectViewModel private let maxCharacterLength = 7 var body: some View { VStack(spacing: 0) { SearchBarRepresentable( text: $viewModel.zipCode, maxCharacterLength: maxCharacterLength, placeholder: "郵便番号を入力する", keyboardType: .numberPad ) .onReceive( viewModel.$zipCode.dropFirst(), perform: { zipCode in if maxCharacterLength == zipCode.count { viewModel.apply( .onSearchZipCode(zipCode) ) self.closeKeyboard() } else { // なにもしない } } ) ... 一部省略 if viewModel.cities.isEmpty { Text("入力した郵便番号は存在しませんでした。\n再度入力をお試しください") .font(.system(size: 11)) .foregroundColor(Color("Error")) .multilineTextAlignment(.center) .frame(maxWidth: .infinity, alignment: .center) .padding(.top, 24) } else { VStack(alignment: .leading, spacing: 0) { ForEach(Array(viewModel.cities.enumerated()), id: \.offset) { index, city in Text("\(city.prefectureName) \(city.cityName1) \(city.cityName2)") .font(.system(size: 12)) .frame(maxWidth: .infinity, alignment: .leading) .contentShape(RoundedRectangle(cornerRadius: 20)) .onTapGesture { viewModel.apply(.onChangeViewStateTapped(.confirm(city: city))) } if index < viewModel.cities.count - 1 { Divider() .padding(.leading, 15) } else { Divider() } } } } Spacer() } .padding(.top, statusBarHeight()) } } また、ViewModelとUIで単一方向のバインディングを実現したいので、ViewModelは外から入力値を受け取ることができるように以下のprotocolに準拠させておきます。
protocol UnidirectionalDataFlowType { associatedtype InputType func apply(_ input: InputType) } final class DiagnosisRegionSelectViewModel: UnidirectionalDataFlowType { typealias InputType = Input private var cancellables: [AnyCancellable] = [] private let disposeBag = DisposeBag() // Combine private let onSearchZipCodeSubject = PassthroughSubject<String, Never>() // MARK: Input enum Input { case onSearchZipCode(String)[f:id:ohayoukenchan:20220329104948p:plain][f:id:ohayoukenchan:20220329104948p:plain] ... 略 } func apply(_ input: Input) { switch input { case .onSearchZipCode(let zipCode): onSearchZipCodeSubject.send(zipCode) ... 略 } } ... 略 こうすることでviewModelの外から viewModel.apply(.onSearchZipCode(zipCode))のようにviewModelへ値を流すことができます。swiftUIの .onTapGesture に複雑な処理を書かないことでコードの見通しが良くなっていると感じています。
最後に iOS13だとGeometryReaderをうまく初期化できなかったり、.ignoresSafeArea(.keyboard, edges: .bottom) が非対応なのでkeyboardを開いたときに画面を押し上げる処理をわざわざ自前で用意しないといけなかったり NSTextAttachment の色が変わらないなど、毎施策必ずといっていいほどiOS13への対応を行っていました。追加でiOS13向けの対応をしなければいけないことを考えると、サポートバージョンがiOS14以降になってからSwiftUIを導入したほうが無難かなという印象です。
近いうちに弊社アプリもサポートバージョンの見直しを行い、iOS14以降でサポートされている StateObject や LazyVGrid なども使えるようになり、ますます開発が楽しくなってきそうです。今後も引き続きシステムを長持ちさせる力を養っていくぞい。
SageMakerとStep Functionsを用いた機械学習パイプラインで構築した検閲システム(後編)
コネヒト
2022-03-28 10:04:36
皆さん,こんにちは!機械学習エンジニアの柏木(@asteriam)です.
今回は前回のエントリーに続いてその後編になります.
tech.connehito.com
はじめに 後編は前編でも紹介した通り以下の内容になります.
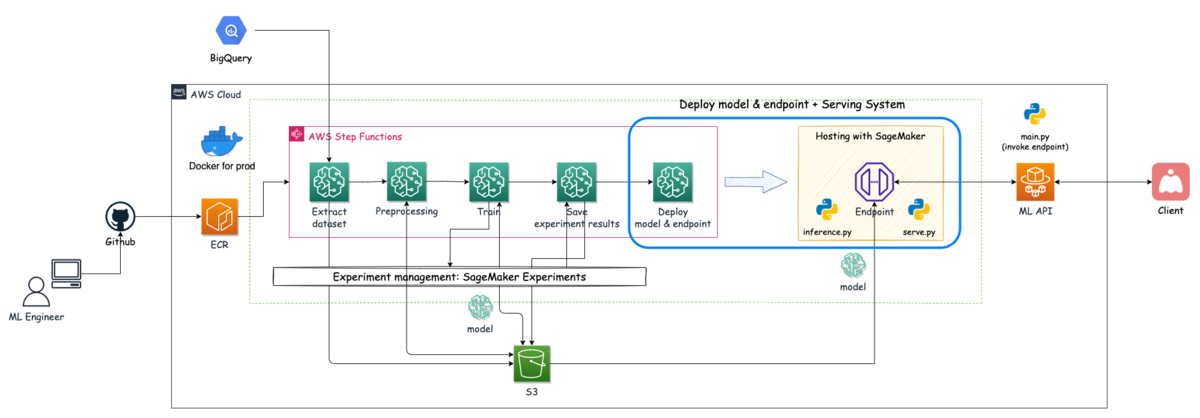
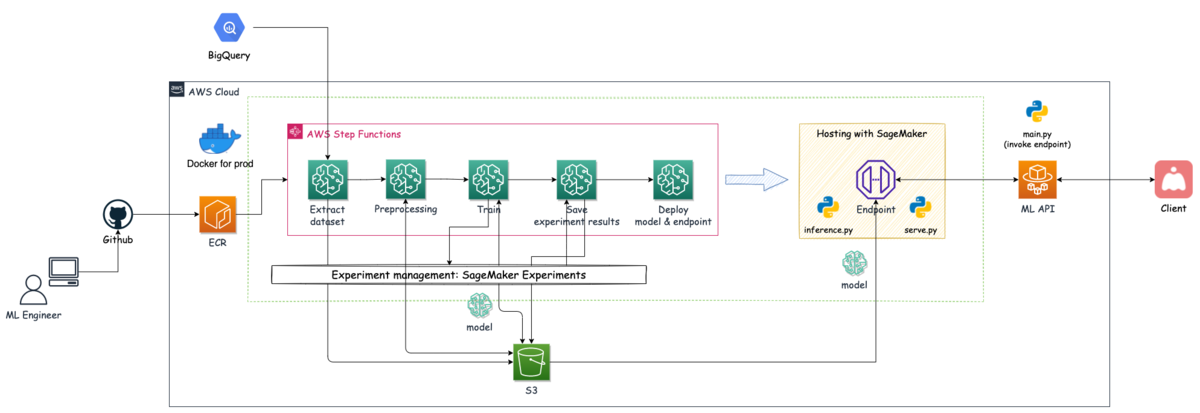
後編:SageMakerのリソースを用いてモデルのデプロイ(サービングシステムの構築)をStep Functionsのフローに組み込んだ話 モデル学習後の一連の流れで,推論を行うためにモデルのデプロイやエンドポイントの作成をStep Functionsで実装した内容になります. 今回紹介するのは下図の青枠箇所の内容になります.
検閲システムのアーキテクチャー概略図
目次
はじめに Step Functionsを使ってサービングシステムを構築する方法 学習済みモデルを含んだ推論コンテナの設定(モデルの作成) エンドポイントの構成を設定 エンドポイントの作成とデプロイ 機械学習システムを開発して おわりに Step Functionsを使ってサービングシステムを構築する方法 Step Functionsのグラフインスペクターに示された処理のうち赤枠部分が今回の処理になります.
No. ステップ名 SageMakerのアクション 処理内容 5 Model-Creating-Step CreateModel 推論コンテナの設定とモデルの作成 6 EndpointConfig-Step CreateEndpointConfig エンドポイントの設定 7 Endpoint-Creating-Step CreateEndpoint エンドポイントの作成とモデルのデプロイ Step Functionsのグラフインスペクター
サービングシステムを構築するために,3つの処理をStep Functionsに組み込んでいます.
モデルの作成と推論コンテナの設定 エンドポイントの構成を設定 エンドポイントの作成とモデルのデプロイ また,サービングシステム・ML API・Clientの関係性を説明するために,システム全体から該当箇所を切り取った図を下に載せています.
サービングシステム
それぞれの役割を説明すると
Client⇄ML API ClientはML APIに対して,推論を行うために必要なデータをPOSTする ML APIは正常投稿 or 違反投稿どちらかを表すフラグ値(0 or 1)をClientに返却する ML API⇄推論エンドポイント(サービングシステム) ML APIは検閲する生のテキストを情報として詰め込んで推論エンドポイントをinvokeする # ML APIの推論エンドポイントをinvokeする処理 import json import boto3 # SageMakerクライアントを作成 client = boto3.client("sagemaker-runtime") # 推論エンドポイントをinvoke input_text = {"text": "推論対象のデータ"} response = client.invoke_endpoint( EndpointName='エンドポイント名', Body=json.dumps(input_text), ContentType='application/json', Accept='application/json' ) # 結果を受け取る result_body = json.load(response['Body']) # 違反確率 pred = float(result_body['predictions']) # 結果の表示 print(pred) サービングシステムはテキストの前処理を行った後に学習済みモデルによる推論を行い,違反確率をML APIに返却する サービングシステムはS3に保存されているモデルアーティファクトをロードしてデータを待ち受けている それでは,サービングシステムを構築する部分を紹介していきます.
学習済みモデルを含んだ推論コンテナの設定(モデルの作成) この処理ステップでは,「モデルの作成」を行います.この処理を行う上で用意するコードは以下になります.
今回も公式のサンプルコードを参考にしたので,確認してみて下さい.
参考: amazon-sagemaker-examples/advanced_functionality/scikit_bring_your_own
用意するコード
Dockerfile.cpu(今回はgpu版のDockerfileも使用しているため.cpuを付けて区別しています) 推論エンドポイントとしてデプロイするコンテナ ファイル内でserve.pyの実行権限を与えておく必要があります serve.py NginxとGunicornを起動するPythonスクリプトで,コンテナ起動時に実行されるスクリプト 実行されるコマンド: docker run <イメージ> serve 公式のサンプルをそのまま流用 inference.py Flaskアプリで,独自の処理を書くことができ,リクエストに応じて機械学習モデルの読み込みや推論処理を行う 今回は生データを受け取り,シーケンスに変換し推論を行う ヘルスチェック時にモデルのロードを行う # inference.py """推論を行うflaskサーバー 生のテキストデータを受け取り,モデルに入力できる形式に変換する BERTモデルに変換したデータを入力することで推論を行う """ import json import os import sys import traceback from typing import List, Tuple import numpy as np from flask import Flask, Response, jsonify, make_response, request # Tensorflow import tensorflow as tf # Transformers - Hugging Face from transformers import AutoTokenizer, TFBertModel # モデルに使用するパラメータ MAX_LENGTH = 512 MODEL_NAME = 'cl-tohoku/bert-base-japanese-whole-word-masking' SAVED_MODEL_NAME = 'bert_model.h5' # 後述のCreateModelのパラメータModelDataUrlに指定するS3に置かれたモデルファイルパスと同期している prefix = "/opt/ml/" model_path = os.path.join(prefix, "model") tokenizer_bert = AutoTokenizer.from_pretrained(MODEL_NAME) def text2features(texts: List[str], max_length: int) -> List[Tuple[np.ndarray, np.ndarray, np.ndarray]]: """テキストのリストをTransformers用の入力データに変換 input_ids, attention_mask, token_type_idsの説明はglossaryに記載されている cf. https://huggingface.co/transformers/glossary.html Args: texts (List[str]): 分類対象のテキストデータが入ったリスト max_length (int): 入力として使用されるシーケンスの最大長 Returns: List[Tuple[np.ndarray, np.ndarray, np.ndarray]]: input_ids, attention_mask, token_type_idsが入ったリスト """ shape = (len(texts), max_length) input_ids = np.zeros(shape, dtype="int32") attention_mask = np.zeros(shape, dtype="int32") token_type_ids = np.zeros(shape, dtype="int32") for i, text in enumerate(texts): encoded_dict = tokenizer_bert.encode_plus(text, max_length=max_length, pad_to_max_length=True) input_ids[i] = encoded_dict["input_ids"] attention_mask[i] = encoded_dict["attention_mask"] token_type_ids[i] = encoded_dict["token_type_ids"] return [input_ids, attention_mask, token_type_ids] class ScoringService(object): """モデルのロードと受け取ったデータから推論を行う """ model = None @classmethod def get_model(cls): """事前にロードできていない場合はモデルをロードする """ if cls.model is None: cls.model = tf.keras.models.load_model(os.path.join(model_path, SAVED_MODEL_NAME), compile=True) return cls.model @classmethod def predict(cls, input: List[Tuple[np.ndarray, np.ndarray, np.ndarray]]) -> float: """入力データに対して,推論を行う Args: input (List): 推論対象のデータで,リストの要素に対して推論を行う """ loaded_model = cls.get_model() return loaded_model.predict(input) # サービング予測用のflaskアプリ app = Flask(__name__) @app.route("/ping", methods=["GET"]) def ping(): """コンテナの動作とヘルスチェックを行う,モデルのロードが成功すればヘルス判定される """ health = ScoringService.get_model() is not None status = 200 if health else 404 return Response(response="", status=status, mimetype="application/json") @app.route("/invocations", methods=["POST"]) def inference(): """ 毎分毎にデータが送られてきて,リアルタイムで推論を行う. テキストデータを受け取り,モデルが受け入れられる形式に変換を行い,予測確率(0.0~1.0)を返す. """ # データを受け取って,モデルに入力できる形式に変換する data = request.get_data().decode("utf8") data = json.loads(data) text = text2features([data['text']], MAX_LENGTH) predictions = ScoringService.predict(text) return make_response(jsonify(predictions=str(predictions[0][0])), 200) nginx.conf Nginxの設定ファイル 8080番ポートで /pingもしくは /invocationsにアクセスがあった場合に,Gunicornに転送する 公式のサンプルをそのまま流用 wsgi.py Gunicornの設定ファイル 推論コード(inference.py)をimportする 用意するコードからわかるように,サービングシステムの実態はWeb ServerにNginx,Application ServerにGunicornを使いフレームワークとしてFlaskを利用しています.
これらのコードを用意したら,イメージをECRに登録し,Step Functionsの定義設定を行います.
CreateModelで主に設定する内容
モデルに名前を付ける 推論コンテナの設定 推論コード サーブファイル アーティファクト(=モデル)のパス設定 イメージ "Model-Creating-Step": { "Type": "Task", "Resource": "arn:aws:states:::sagemaker:createModel", "Parameters": { "PrimaryContainer": { "ContainerHostname.$": "States.Format('{}-{}', 'prod-sample-con', $$.Execution.Name)", "Environment": { "PYTHON_ENV": "prod" }, "Image": "<アカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/sample:latest-cpu", "Mode": "SingleModel", "ModelDataUrl.$": "$.ModelArtifacts.S3ModelArtifacts" }, "ExecutionRoleArn": "arn:aws:iam::<アカウントID>:role/StepFunctions_SageMakerAPIExecutionRole", "ModelName.$": "States.Format('{}-{}', 'prod-sample-m', $$.Execution.Name)" }, "Catch": [ { "ErrorEquals": [ "States.ALL" ], "Next": "NotifySlackFailure" } ], "ResultPath": null, "Next": "EndpointConfig-Step" } ModelDataUrl: TrainingJobの出力結果から参照しており,モデルが保存されているS3のパスを指定します.ここで指定したパスが’/opt/ml/model’に同期されるので,推論コードで呼び出してモデルをロードすることができます. ExecutionRoleArn: ロールにアタッチするポリシーはSageMaker Rolesを参考にしてみて下さい.ここで嵌ってしまったのですが,Actionに"iam:PassRole"が必要になるので注意です. エンドポイントの構成を設定 この処理ステップでは,モデルをデプロイするために使用する「エンドポイントの構成を作成」を行います.
CreateEndpointConfigで主に設定する内容
デプロイするモデルの指定(CreateModel時に付けたモデルの名称) プロビジョニング用のリソース エンドポイント構成の名前 "EndpointConfig-Step": { "Type": "Task", "Resource": "arn:aws:states:::sagemaker:createEndpointConfig", "Parameters": { "EndpointConfigName.$": "States.Format('{}-{}', 'prod-sample-ec', $$.Execution.Name)", "ProductionVariants": [ { "InstanceType": "ml.t2.large", "InitialInstanceCount": 1, "ModelName.$": "States.Format('{}-{}', 'prod-sample-m', $$.Execution.Name)", "VariantName.$": "States.Format('{}-{}', 'prod-sample-v', $$.Execution.Name)" } ] }, "Catch": [ { "ErrorEquals": [ "States.ALL" ], "Next": "NotifySlackFailure" } ], "ResultPath": null, "Next": "Endpoint-Creating-Step" } InstanceType: 推論サーバーのマシンスペック(インスタンスタイプ)をここで決めます.今回は最低スペックのml.t2.mediumだとメモリ不足になったので,メモリ8GBのマシンを選択しました.この辺りは常時稼働しているので費用面と相談しながらスペックを決める必要があると思います. エンドポイントの作成とデプロイ この処理ステップでは,エンドポイント設定を用いて「エンドポイントの作成」を行います.ここで最終的に設定されたリソースを起動し,モデルをその上にデプロイします.
CreateEndpointで主に設定する内容
デプロイするモデルの指定(CreateModel時に付けたモデルの名称) 使用するエンドポイント構成の指定(CreateEndpointConfig時に付けたエンドポイント構成の名称) エンドポイントの名前 "Endpoint-Creating-Step": { "Type": "Task", "Resource": "arn:aws:states:::sagemaker:createEndpoint", "Parameters": { "EndpointConfigName.$": "States.Format('{}-{}', 'prod-sample-ec', $$.Execution.Name)", "EndpointName.$": "States.Format('{}-{}', 'prod-sample-e', $$.Execution.Name)" }, "Catch": [ { "ErrorEquals": [ "States.ALL" ], "Next": "NotifySlackFailure" } ], "End": true } 処理が正常に完了するとSageMakerのコンソール上でエンドポイントを選択すると,指定したエンドポイント名のステータスが「InService」になっていることを確認できます.
SageMakerのコンソール画面 - エンドポイント
また,エンドポイントを誤って削除したり,想定とは違う状態だった場合にロールバックが必要になることがありますが,これはモデルとエンドポイント設定が残っていればいつでも復元可能です.エンドポイントの作成は手動でもできるのでSageMakerのコンソールから設定すると良いと思います.
機械学習システムを開発して 今回新しく検閲システムを開発し,その中でデータ抽出からモデルの学習,そしてモデルのデプロイまで一気通貫した機械学習パイプラインを構築しました.このプロジェクトでは,推論システムも構築する必要があったため,そもそもStep Functionsでモデルのデプロイまで持っていけるのかというところから技術検証したり,推論速度といった非機能要件なども検討して処理を考える必要があったりと難しい部分もありました.また,PoCは別のメンバーが担当していたこともあり,Jupyter Notebookからプロダクション用のシステムに合わせたコードを作り上げる部分や再現性を取る部分でも苦労がありました.
これらの苦労の甲斐あって?無事に本番稼働しているこのシステムの状況としては,コスト削減という部分で,当初の期待通りxx万円/月のカットに寄与できていたり,サービス品質向上という部分では,質問の回答率が上がるといった成果が出ています.
一方で,推論の精度面で多少の検知漏れがあったりと少し改善が要求されたりする可能性があり,この辺りは継続的に改善が必要で,まさにMLOpsだなと感じています.
また,この取り組みは全ての投稿をチェックすることから,より違反確率が高い投稿のみを重点的にチェックすることができるため,作業量が減り作業者の精神的負荷が減ったり,作業効率化も上がるといった作業者側のメリットだけでなく,モデルが違反確率が高いと返した投稿の中にも問題ない(正常)投稿も含まれているため,これらを人間が正しく判定し直すことで,今後のモデル改善時に使える有効なアノテーションデータとして蓄積することができるメリットもあります.これらの取り組みはまさに「Human-in-the-Loop」が上手く機能している状態ではないでしょうか.
おわりに 今回は前編・後編と2つの記事に分けてSageMakerとStep Functionsを用いた機械学習パイプラインにより構築した検閲システムの内容を紹介しました.特にStep FunctionsでのTrainingJobの活用例やモデルのデプロイ部分を組み込んだパイプラインに関する事例はあまり公開されていない内容かと思うので,是非参考にして頂ければと思います.
今回の取り組みはCSチームと連携して進めたことにより良い成果が出つつあると思うので,これからもサービスの品質向上やグロースに対して他チームと協力する中で機械学習を導入することでよりその価値を発揮していければと思います.
最後に,コネヒトではプロダクトを成長させたいMLエンジニアを募集しています!!(切実に募集しています!)
もっと話を聞いてみたい方や,少しでも興味を持たれた方は,ぜひ一度カジュアルにお話させてもらえると嬉しいです.(僕宛@asteriamにTwitterDM経由でご連絡いただいてもOKです!)
www.wantedly.com
Jest + react-testing-library でフロントエンドテストをコツコツ積み上げている話
コネヒト
2022-03-28 12:07:56
こんにちは。コネヒト歴7ヶ月目のWebエンジニアの古市です。
私の所属するチームではReactで構築されたCMSを開発しています。 Atomic Designに則り、コンポーネントを Atoms/Molecules/Organisms/Pagesの区分で作成しています。このうち、Atoms,Molecules,OrganismsについてはJest+react-testing-libraryの組み合わせで必ずテストを書くようにしています。 今回は実際に書いているテストコードを例に挙げながら、どのような点をテストコードで担保しているか、また、テストを積み重ねるための施策について説明いたします。
具体的なテストコード これは業務で書いているテストコードを抽象化した一例です。 以下のような構造のコンポーネントのテストだとイメージしていただければと思います。
名前が表示される アバター画像が表示される コメントを記入するinputと、付随するラベルが存在する 「更新」と書かれたボタンを押下で変更内容をupdateする import React from 'react' import { fireEvent, render, screen, waitFor } from '@testing-library/react' import { SomeComponent } from 'components/organisms/SomeComponent' import client from 'api/client' // 実装したAPI // post時のAPIをモック化 jest.mock('api/client') const mockedAPI = client.post as jest.Mock // コンポーネントに投入する初期モックデータ const mockData: MockData = { id: 123, name: 'コネヒト太郎', image: 'https://some-url/320x480.png', label: 'テキスト', comment: '', } まずテストを書くために必要なライブラリとテスト対象のコンポーネントをimportします。 そしてコンポーネントに流し込むモックデータを一番最初に定義します。
// describe -> test の順番で記述 describe('<SomeComponent />', () => { test('should render component', () => { const mock: MockData = mockData render(<SomeComponent mockData={mock} onClickUpdate={() => {}} />) // 名前、アバター画像、ラベルの描画チェック expect(screen.getByText(mock.name)).toBeInTheDocument() expect(screen.getByRole('image')).toBeInTheDocument() expect(screen.getByLabelText(mock.label)).toBeInTheDocument() // textareaの初期値チェック expect(screen.getByRole('textbox', { name: 'テキスト' })).toHaveDisplayValue(mock.comment) // ボタンの描画チェック expect(screen.getByRole('button', { name: '更新' })).toBeInTheDocument() }) 最初にコンポーネントが描画されることをテストコードで確認します。 testing-libraryを使う場合、screen.getBy*というQueryメソッドでDOM要素の有無を特定することが定石ですが、アクセシビリティに則り使用する優先順位が以下のように定められています。
getByRole getByLabelText, getByPlaceholderText getByText, getByDisplayValue テストコードでDOM要素を特定するときも、アクセシビリティの観点からなるべくこの優先順位を無視しないよう心がけています。(どうしても難しい時にtestByIdなどを活用します。) 他にも、書くメソッドの使用優先順位が定められているので詳しくは公式サイトのリファレンスをチェックしてください。
また、過去に自身でQueryの優先順位について整理してLTで発表したスライドもあるので、こちらもぜひご覧いただけると幸いです。
React Testing Library の Query について整理してみた - Speaker Deck
それではテストの続きです。 2番目のテストスイートでは要素の変更が反映されるかをチェックしていきます。
test('Events should be called', () => { const onClickUpdate = jest.fn() render(<SomeComponent mockData={mock} onClickUpdate={onClickUpdate} />) // テキストアイテムのテキスト変更のonChangeイベントをテスト const textareaContent = screen.getByRole('textbox', { name: 'テキスト' }) fireEvent.change(textareaContent, { target: { value: 'テキストを変更しました' } }) expect(screen.getByDisplayValue('テキストを変更しました')).toBeInTheDocument() // 更新ボタンのonClickをテスト fireEvent.click(screen.getByRole('button', { name: '更新' })) expect(onClickUpdate).toHaveBeenCalled() }) 「更新」をボタン押下したときに呼び出されるメソッドはjest.fn()でモックしておきます。 textboxへの新しい値の入力や、ボタンのクリックなどのイベントはfireEventメソッドでモックし、伝達することができます。
最後に、テキストの更新が意図通り行われた時、APIにリクエストが送られているかをテストします。
test('Save API should be called', async () => { mockedAPI.mockResolvedValueOnce({ status: 200, data: { item: { ...mock, comment: 'テキストを変更しました' }, }, }) const mockUpdated = { ...mock, comment: 'テキストを変更しました' } const onClickUpdate = jest.fn() render(<SomeComponent mockData={mockUpdated} onClickUpdate={onClickUpdate} />) // テキストアイテムの文言を変更 fireEvent.click(screen.getByRole('button', { name: '更新' })) await waitFor(() => expect(mockedAPI).toHaveBeenCalledTimes(1)) expect(screen.getByDisplayValue(mockUpdated.comment)).toBeInTheDocument() }) }) コンポーネントに変更後の comment を流し込み、更新ボタンを押した時に、テストコードの冒頭でモック化したAPIが呼び出され、正常なステータスと更新後の値がコンポーネントに反映されているかを上記でテストしています。モック化したAPIを叩く時は、waitFor(() => ...の前にawaitを記述しないと正しく結果が得られません。 以上は一例ですが、正常系のテスト以外でも、コンポーネントによっては4xxのバリデーションエラーや5xxのサーバーエラー発生時の挙動をテストコードで補完する場合があります。
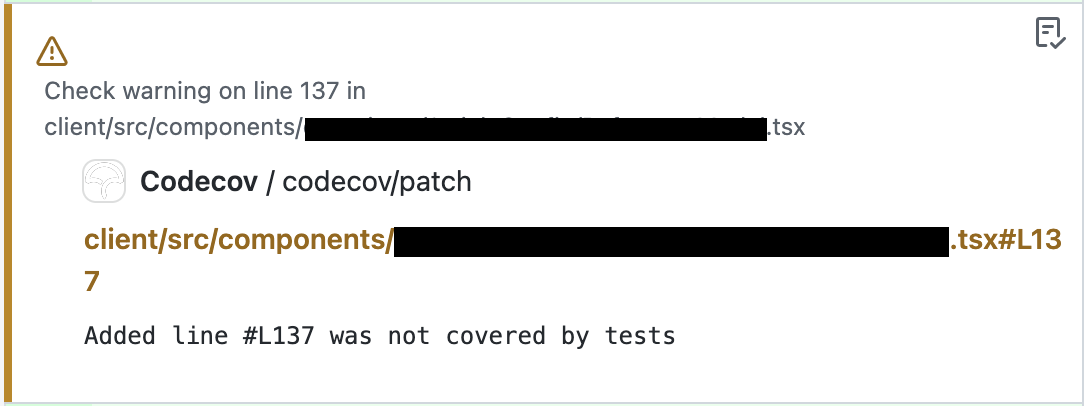
テストを積み重ねるための工夫 開発者がテストを必ず書くことを促すため、プロジェクトのリポジトリ内にCodecovをGitHub ActionのWorkflowに導入しています。Pull Requestを送信するとリポジトリの最新(main)と当該PRのdiffを視覚的に把握することができます。また、最低カバレッジ率を .yml ファイル内に記載することができます。 pages以外のコンポーネントを作成してPull Requestを送信した時、テストが書かれていないまたはテストケースが足りていない場合に、Codecovがカバレッジ低下の警告を出し、テストケースを追加すべき場所にコメントを自動的に付けます。
Codecovが表示するdiff テストが不足している場合に出す警告のコメント 上記のようにカバレッジが下がっている状態ではCIが通過せず、コードレビューに提出することができません。独力で正確にテストコードを追加できない場合には他のメンバーにアドバイスをもらったり、モブプロ / ペアプロで解決させるように取り組んでいます。現時点ではカバレッジ率を90%にしていますが、これをもう1段階高く設定することを目標にしています。
終わりに テストコードの解説が大半を占めてしまいましたが、チーム内でのフロントエンドテストへの取り組みについて説明いたしました、まだJestやtesting-libraryの使い方でつまづく時があるため、社内で知見を共有しあい、今後も真摯にテストに向き合いつつツールへの習熟度を高めていきたいと思います。最後までお読みいただきありがとうございました。
PR コネヒトでは React を使ってテストも書きたいエンジニアを募集しています!
hrmos.co
Win Sessionで元気に目標を達成するチームづくり
コネヒト
2022-03-25 05:51:14
こんにちは、コネヒトでエンジニアをやっているあぼ(aboy)です ԅ( ˘ω˘ԅ)
今回は私の所属するテクノロジー推進部というチームで実施しているWeekly Win Session(ウィンセッション)について紹介したいと思います。始めてから5ヶ月ほど経ち、チームのイベントとして定着しました。Win Sessionのひとつの事例として何かの参考になれば幸いです。
ちなみにWin Sessionとは以下のようなもので、OKRの文脈で出てくることが多いです。
週の終わりに今週はどんな結果だったのかを確認し、立て直し策を具体的に決めるまで行うことを主目的にミーティングを行います。これを、ウィンセッションと呼びます。ここで大切なことは、結果にかかわらず、各メンバーが高い目標に挑んだことを承認・賞賛することです。
奥田和広. 本気でゴールを達成したい人とチームのためのOKR (Japanese Edition) (p.143). Kindle 版.
一般的なWin Sessionの説明はさらっと引用での紹介にとどめ、さっそく私のチームの話に入ります。
なぜWin Sessionを始めたか 理由は大きくわけて2つあります。
チームが元気な状態で目標を達成できるようにする コネヒトでは基本的に6ヶ月ごとに目標を立て、達成させるための作戦を考え、動いていくのですが、終わり間際に追い込み疲れている印象がありました。 なのでチームの作戦を立てる段階で「元気な状態で目標を達成する」というゴールイメージをつくりました。 短いサイクルで体力と気力を回復しながら前に進んでいくための手段として、賞賛を行うWin Sessionは相性が良さそうに見えました。 今週も頑張った!来週も頑張るぞ!って思える場を作りたい 私のチームでは毎週の定例で目標の進捗共有や議論などを行っていて、どちらかというと課題発見や課題解決に重きが置かれていました。これまでを振り返りつつ先のことを考える重要な時間です。 そういった目標達成に向けたカッチリした共有や議論と、やっていることや業務連絡など非同期でも十分な共有、そのどちらでもない「やったことを称える時間」をつくることで、メリハリが生まれるのではないかと考えました。 どういうふうにやっているか ルールというほどカタいものではないですが、やっていくうちにある程度型ができてきたので紹介します。やり方はつどつど見直しています。
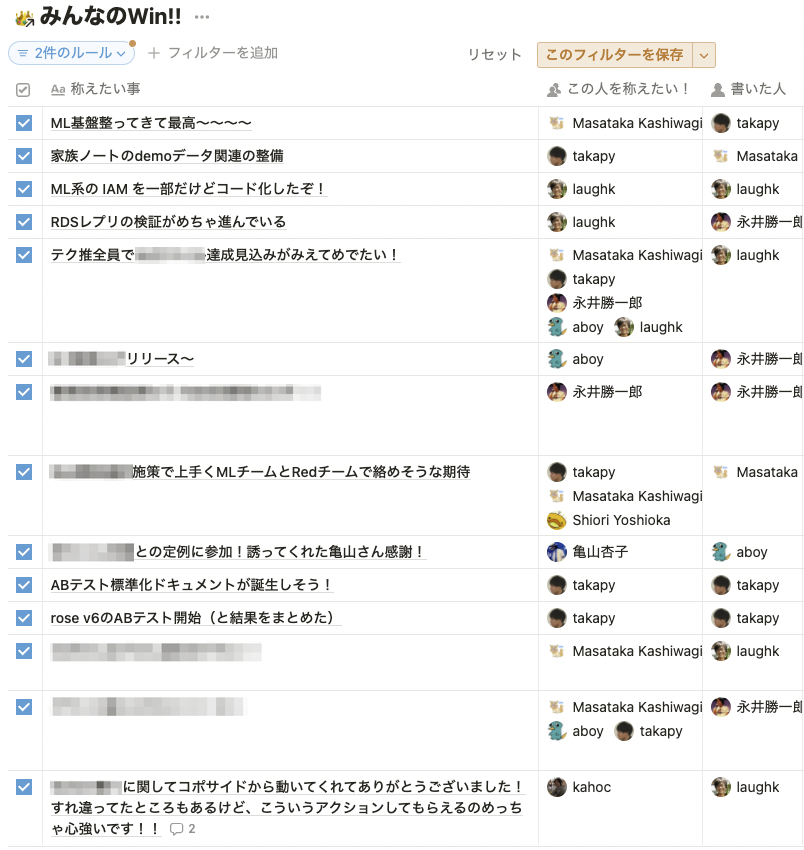
毎週金曜日の夕方に開催 毎週開催することによって1週間のリズムが生まれること、またWin Sessionのような良い気持ちで終わるイベントで1週間を締めることで、1週間を労い、来週のパワーに繋がることを期待しています。 開始当初は18:30開始としていましたが、そもそもコアタイム外であること、コロナ禍における家庭環境、Win Sessionがあるから早めに上がれないことは避けたい、など考慮して現在は17:00開始で定着しました。 お酒を飲みながら参加しても良い(ただし飲んだらその後仕事は禁止)というルールで始めましたが、まだお酒を飲む人は現れません。(そして私も飲んでない) チーム日報を見返しながら1人ずつ発表 私のチームでは、メンバー全員で同時編集する形で日報を書きながら日々仕事をしており、その日報を1週間分見返しながら、自分のWinを3~5分程度で発表していきます。 自分の仕事を振り返り、自分はこんなことやったんだぞってアピールしみんなで称えます。 1週間分のチーム日報をまとめて振り返るのが結構大変なので、最近は日々発見したWinを1つの場所(Notionを使っています)に溜めておき、それを見ながら進めるようなやり方にトライしています。 他の人のWinも見つける チーム日報の効果として、自分以外のチームメンバーの仕事が目に触れやすいというのがあります。専門分野が違うメンバーが集まり共通の目標を追う僕たちにとって、自分の専門分野ではない領域の仕事に興味を持ったりフォローしたりすることには価値があります。 ですので、その人自身はWinだと思っていないようなことを発見してあげることもあります。 議論はしない 議論をする場ではないため議論はしません。これと開催時間が明確なルールかもしれません。 物理的に拍手 👏 する Win Sessionは今まで全てオンラインで行っていますが、Winの発表が終わったら「お疲れ様でした」と共に物理的に拍手 👏 をするようにしています。これは自分や他人のWinを聞くと自然と拍手したくなったからしてる、以上の理由はないのですが、結構気持ちがいいです。そういえばリモートワークになってから、ビデオチャットに「88888888888」みたいに書き込むことはあっても物理的な拍手することってあんまりないな、と思っています。皆さんはどうですか...? ԅ( ˘ω˘ԅ) 「良い週末を!」で締める 金曜日の夕方に開催しているのでこうしています。締まりが良いですし、締め方に悩む必要もないので一石二鳥です。 とある週のWin Sessionの様子(Notion)
どんな効果を実感しているか 5ヶ月ほど続けて、チームメンバーからは以下のようなフィードバックが集まっています。
準備なしで参加できるのがGood(ゆるーい感じのコミュニケーションの場という感じ) 1週間やったった!来週もやったるか!という感情が以前より湧くようになった 週のしめくくりとしてちゃんと終わりを意識できるのが良い 1週間の締めのイベントとして定着したのは間違いない感じ ゆるいけれど「1週間の自チームからみたコネヒトの様子」が可視化されるようになった感じがある 今週もお疲れさまでしたーと解散していくのはとてもよい! 締めの今週もお疲れさまでしたでzoom越しで 👋 するの好き みんなのwinを探す方式を取っているので、自然と他人の良かったところ(≒アウトプット)を探す癖?みたいなものがついたかも?(本当か?) 今までよりチームメンバーへの興味度合いが上がっているのかもしれない(本当か?) チームの1週間にメリハリをつけるイベントとして定着したといえます。
一方で、以下のようなフィードバックもあります。
他薦もアリになってからは自薦のWinが減った感覚があり、自薦形式のほうが聞いていて好きかもしれない Winまでいかなくても、強いて言うならこんなことやって個人的には小さなWinです、みたいなのが個々人フォーカスして聞けるのもいいよね 自分で自分のWinを発表するという形から、他人のWinを紹介する(「こんなことやっていたから称えたい」)ケースが増え、ここまではやり方の範疇ですがもっと言うとチーム外の人のWinが出てくることも増えました。この辺りは最初に決めた仕組みに固執せず柔軟にチームで考え決めていきたいところです。目的が変わると参加者の期待値も変わるのでそこは丁寧にいきたいところです。
それから、Win Sessionがメリハリをつけるようなイベントだからこそのお悩みもありました。
業務が立て込んでいるとWin Session後にまたガッツリ仕事に戻るのが大変 あとは、お酒でも飲みながらワイワイやる会があってもいいかもしれません。
Win Session後すぐに上がってお酒を飲むとかもうちょっとやりたかった たしかに初期コンセプトは飲みながらでもみたいなノリだったよね。やれてない ...で、結局チームの目標は達成できたのかというと、無事達成できそうです。これが一番嬉しいです。Win Sessionとの因果関係は分かりませんが、これはチームのためのイベントなので、「チームのためになっているか?」を常に考えこれからもチームで試行錯誤していきます。
おわりに 私のチームでのWin Session事例を紹介しました!この記事を書くにあたって初めてWin Sessionをやった直後の反応(Slack)を見返してみました。最初なので手探りでしたが、何となくいい感じだったな〜と思えました。Win Sessionが気になった方は、ぜひ一度試しみてください〜。
初めてWin Sessionをやったときの反応(最初の頃は18:30開始でした)
We are hiring!! コネヒトでは、プロダクトを成長させたいWebエンジニアを募集しています!
ライフイベント、ライフスタイルの課題解決をするサービスに興味がある方 是非お話できれば嬉しいです。
下記リンクからお気軽にご連絡お待ちしています!
www.wantedly.com
既存プロダクトのCakePHPのアップグレード戦略
コネヒト
2022-03-25 01:00:00
既存プロダクトのCakePHPのアップグレード戦略 こんにちは。サーバーサイドエンジニアをやっている西中です。
花粉症に悩まされているので最近空気清浄機を購入しました。こころなしか症状が緩和している気がしています。
前回はCakePHP4.3にアップグレードする際に躓きがちなphpunitの変更ポイントをいくつか紹介させていただきました。
実はこのCakePHPのアップグレード対応は段階的に行っていました。
CakePHP段階的なアップグレード対応 私が携わっているこのプロダクトは2018年11月にリリースされました。 リリースした時点ではCakePHPのバージョンは3.6でした。
いきなりCakePHP3.xからCakePHP4に上げてしまうとアップグレード対応の差分が大きくなってしまい、対応に時間がかかってしまうという問題があるため、段階的にアップグレード対応しようという判断になりました。
少し話が逸れてしまいますが、弊社では各開発チームごとにスクラムを組んでアジャイル開発を行っています。アジャイル開発と言っても実際の運用はチームごとに異なりますが、当プロダクトでは1スプリントの中で何度もリリースすることがあります。
GitHubフローにおけるブランチ開発 また、弊社ではGitHubフローに沿って開発を行っています。 このアップグレード対応という「保守対応」と、アウトカムを支えるための「施策運用対応」を並行で進めることになるため、ブランチ運用としてはアップグレード対応用のFeatureブランチとそれぞれの試作用のFeatureブランチが必要になってきます。
施策運用対応のためのブランチは都度都度mainブランチにマージされていくため、保守対応のためのブランチとの差分が増えていき、定期的にmainブランチを取り込みアップグレード版に合わせた形に都度都度修正する必要が出てきます。 (最新のパッチを保守対応用ブランチに適用させていくバックポート対応のイメージです)
この都度都度修正の対応が大きめの施策になればなるほどCakePHPのバージョンの差異に合わせた修正の規模が大きくなってしまう問題もあり、その分工数が余計にかかってしまいます。
これらの事情から、保守対応ブランチをmainブランチへマージするまでの時間を短くするために、あえて段階的にアップグレード対応を行うということになったのです。
また、以前CakeFestで紹介されたスライド(CakePHP - The Road Ahead)でも、2.xから3.0.0にアップグレードしたときに変更量が多くて大変だったということが述べられています。
実際にサービス提供しているプロダクトの場合、安全に倒すためにも段階的なリリースを計画するのが良さそうですね。
CakePHP3.6から3.10へ まず、CakePHPのバージョンを3.6からCakePHP3.xの最新のバージョンである3.10にアップグレードしました。 実はこの3.6から3.10にアップグレードする際の変更量が一番多かったのではないのかと思っています。
一番大きな影響が受けたのがテストのFixture周りです。
今までは Model クラスをテストケース内で使用する際には TestCase のメンバ変数内で実際の DBに格納されているテーブル名に合わせてModel名を以下のように Snake Caseで記述していましたが、CakePHP3.6以降ではModel名をUpper Camel Caseで記述する必要があります。
TestCase::$fixtures にてアンダースコアー形式のフィクスチャー名を使用することは非推奨です。 代わりにキャメルケース形式の名前を使用してください。例えば、 app.FooBar や plugin.MyPlugin.FooBar です。 3.7 移行ガイド - 3.10 より引用
public $fixtures = [ 'app.cities', 'app.countries', 'app.country_languages', ]; public $fixtures = [ 'app.Cities', 'app.Countries', 'app.CountryLanguages', ]; ロジックの変更対応ではないので、一つ一つ対応していけば良いのですが、テストケースの数が多ければその分対応する場所も多くなってしまいます。
変更量が多いということはテストファイルによって、ある程度テストの網羅性が担保されているとも考えられるので、この変更は喜んで進めていきましょう。
さいごに どこの会社・プロダクトでも保守対応は置いてけぼりになりがちになってしまい、フレームワークのバージョンが置いていかれてしまうことが多いと思います。 セキュリティパッチが当てられたりと、フレームワーク側で対応が進められている中で、古いバージョンのまま放置しておくとセキュリティリスクも上がってしまいます。
アウトカムのリリーススケジュールと並行して計画的にバージョンアップを行えるようにしていきたいですね!
あわせて読みたい PHPStanを0.11から1.4へメジャーアップデートした際の知見 - コネヒト開発者ブログ 「こんなところも?」 CakePHP4・phpunitのアップグレードに伴う変更箇所 - コネヒト開発者ブログ CakePHP3から4へのバージョンアップ時に困ったキャッシュ周りの話 - コネヒト開発者ブログ
SageMakerとStep Functionsを用いた機械学習パイプラインで構築した検閲システム(前編)
コネヒト
2022-03-24 08:37:19
皆さん,こんにちは!機械学習エンジニアの柏木(@asteriam)です.
今回はタイトルにもあるようにモデルの学習からデプロイまで一気通貫した機械学習パイプラインをSageMakerとStep Functionsで構築し,新しく検閲システムを開発したお話になります.
こちらのエントリーで紹介されている機械学習を用いた検閲システムの技術的な内容になります.
※ 検閲システムの細かい要件や内容については本エントリーでは多くは触れないのでご了承下さい.
tech.connehito.com
はじめに 今回のエントリーは内容が盛り沢山になっているので,前編と後編の2つに分けて紹介することにします.
前編:SageMaker TrainingJobを用いたモデル学習を行い,SageMaker Experimentsに蓄積された実験結果をS3に保存するまでの話 前回紹介したテックブログ「SageMaker Experimentsを使った機械学習モデルの実験管理」の内容を実際のプロダクション環境に適用した内容になります. 後編:SageMakerのリソースを用いてモデルのデプロイ(サービングシステムの構築)をStep Functionsのフローに組み込んだ話 モデル学習後の一連の流れで,推論を行うためにモデルのデプロイやエンドポイントの作成をStep Functionsで実装した内容になります. 本エントリーはSageMakerとStep Functionsで機械学習パイプラインを構築しようと考えている人や独自の推論処理をSageMakerで動かしたい人向けの内容になります.
これらの内容に関する事例やテックブログは世の中にあまりなく,トライ・アンド・エラーを繰り返すことが多かったので,今後同じようなことを実装しようと考えている人の一助になればと思います.
ソニー創業者の井深大さんも以下のような名言を残されており,今回のプロジェクトは改めてSageMakerとStep Functionsの理解を深めることができ自分自身大きな経験となりました.
トライ・アンド・エラーを繰り返すことが、「経験」「蓄積」になる。独自のノウハウはそうやってできていく。
目次
はじめに アーキテクチャー概要 モデル学習にSageMaker TrainingJobを選択した理由 SageMaker TrainingJobを用いたモデル学習 Step Functionsの定義設定 - モデルの学習を行う処理 SageMaker Experimentsの結果をS3に保存 Step Functionsの定義設定 - 実験結果の保存を行う処理 おわりに アーキテクチャー概要 今回実装したシステムのアーキテクチャー概略図は以下のようになります.本エントリーで紹介するのはAWS Step Functionsで組んだ機械学習パイプラインの部分になります.
MLチームではレコメンドシステムもStep Functionsでパイプラインを組んでおり,今回も既に経験&知見があるStep Functionsを使って機械学習パイプラインを作成することにしました.
検閲システムのアーキテクチャー概略図
Step Functionsによるパイプラインを実行すると,データ抽出・前処理・モデルの学習・実験結果の保存といった処理が行われ,最終的に推論を行うためのモデルのデプロイが行われます.
デプロイされたサービングシステムはML API(ECS: 実行環境はFargate)からエンドポイントをinvokeされることで処理が走り,結果をML APIに返し,その結果をClientに返す流れになります.(ML APIはClientからリクエストを受けます)
SageMakerのCreateProcessingJob / CreateTrainingJobを使ってデータ抽出・前処理・モデル学習/評価・実験結果の保存まで行っており,モデルを含んだ推論コンテナのデプロイとエンドポイントの作成はSageMakerのCreateModel / CreateEndpointConfig / CreateEndpointを組み合わせて実施しています.
参考までに今回作成したStep Functionsのグラフインスペクターは以下のようなものになります.
Step Functionsのグラフインスペクター
今回作成したStep Functionsの処理と対応するSageMakerの処理の対応表は以下になります.
No. ステップ名 SageMakerのアクション 処理内容 1 Dataset-Extracting-Step CreateProcessingJob BigQueryからデータを取得 2 Dataset-Creating-Step CreateProcessingJob 学習と評価用のデータセット作成 3 Model-Training-Step CreateTrainingJob モデル作成 4 Experiments-Saving-Step CreateProcessingJob 実験結果の保存 5 Model-Creating-Step CreateModel 推論コンテナの設定とモデルの作成 6 EndpointConfig-Step CreateEndpointConfig エンドポイントの設定 7 Endpoint-Creating-Step CreateEndpoint エンドポイントの作成とモデルのデプロイ 次からのパートでは,モデル学習時に使用したTrainingJobの話とSageMaker Experimentsに蓄積された実験結果をS3に保存する話に焦点を当てています.
モデル学習にSageMaker TrainingJobを選択した理由 今回構築するパイプラインでは,以下の要素を含んだ方法で実現したいと考えていました.
実験の再現性を担保するために,SageMaker Experimentsに実験結果を保存したい 学習スクリプトはSDKなどAWS特有の記述を意識せずシンプルに作成したいので,面倒な設定はStep Functionsの定義に押し込めたい 一方で,上記を実現する方法としては2パターンあるかなと思います.
ProcessingJobを使い,学習用スクリプト(train.py)とSageMaker SDKを用いたラップ用のスクリプトを使う方法 TrainingJobを用いて,学習用スクリプト(train.py)を使う方法 1つ目の方法に関しては,以前のエントリーで実施した内容で,以前紹介したのはSageMaker Studioから実行した方法ですが,このコードをスクリプト化し,Step FunctionsのProcessingJobで実行する方法になります.こちらはもう少し説明すると,学習用スクリプト(train.py)を用意し,SageMaker SDKのEstimatorクラスを使い用意した学習用スクリプトをラップしたスクリプトを別途用意する必要があります.この場合は,ラップしたスクリプト内部or環境変数として設定用の変数を複数入れてやる必要があるので,複雑になってしまうかなと思います.また,SageMaker SDKのお作法を理解して実装する必要があります.
2つ目の方法は,SageMaker SDKのEstimatorクラスの設定をStep FunctionsのTrainingJobが担う方法です.こちらは設定をStep Functionsの定義に押し込めることができるので,ラップ用のスクリプトを別途用意する必要はなく,学習用スクリプトのみを用意するだけで大丈夫です.こちらの方がコードが複雑にならず,Step Functionsの定義を管理すれば良いです.
今回は2つ目の方法を採用し実装することにしました.(前提として独自のカスタムコンテナイメージを用いる想定です)
※ これらとは別に全てをコード管理して,SageMaker SDKやStep Functions SDKを使ったworkflowを構築する方法もあります.
参考: Amazon SageMaker Processing と AWS Step Functions Data Science SDK で機械学習ワークフローを構築する
SageMaker TrainingJobを用いたモデル学習 それでは実際の設定を見ていきますが,学習用スクリプト(train.py)については具体的な処理は載せることはできないので,実装イメージを載せておきます.
公式のサンプルコードも参考になると思うので,参考下さい.
参考: amazon-sagemaker-examples/advanced_functionality/scikit_bring_your_own
# train.py import argparse import os def main(params): # パラメータの受け取り max_length = params.max_length learning_rate = params.learning_rate epochs = params.epochs batch_size = params.batch_size # 以下にモデル学習に必要な処理を記述する(実際は色々とコードがあるが今回は省略) model_path_prefix = '/opt/ml/model/' model_path = os.path.join(model_path_prefix, 'bert_model.h5') create_model( X_train, y_train, X_valid, y_valid, learning_rate, epochs, batch_size, model_path ) # モデル作成を行う関数: train/validデータやハイパーパラメータなどを引数に渡す ... if __name__ == "__main__": # コマンドライン引数をパースする parser = argparse.ArgumentParser() # モデルのハイパーパラメータ引数 parser.add_argument( "--max_length", type=int, default=512, help="The maximum length of a sentence to use as input" ) parser.add_argument( "--learning_rate", type=float, default=3e-5, help="Learning rate when model is created" ) parser.add_argument( "--epochs", type=int, default=5, help="Number of epochs when model is created" ) parser.add_argument( "--batch_size", type=int, default=12, help="Number of batch size when model is created" ) params, _ = parser.parse_known_args() main(params) 学習したモデルは '/opt/ml/model/' 配下に格納され,このファイルが後述するStep Functionsの定義で指定したファイルパスに同期されます.ここはモデルデプロイ時にも関係してくるので,パス設定は重要になります.
このコードに関する実行権限をDockerfileで与える必要があるので,ここは以前のエントリーの「カスタムコンテナで実行するための準備」の部分を参考にして頂ければと思います.
また,今回はGPU環境での学習になるので,カスタムコンテナイメージを使ってSageMaker TrainingJobを動かす方法は手前味噌ですが,Step Functionsで自作Dockerfileを使ってSageMakerのGPUマシンを動かす方法を参考下さい.
Step Functionsの定義設定 - モデルの学習を行う処理 次にStep Functionsの定義設定でTrainingJobの設定部分だけを取り出して説明していきます.
"Model-Training-Step": { "Comment": "モデル作成処理", "Type": "Task", "Resource": "arn:aws:states:::sagemaker:createTrainingJob.sync", "Parameters": { "RoleArn": "arn:aws:iam::<アカウントID>:role/StepFunctions_SageMakerAPIExecutionRole", "TrainingJobName.$": "States.Format('{}-{}', $$.Execution.Name, $$.State.Name)", "AlgorithmSpecification": { "EnableSageMakerMetricsTimeSeries": true, "MetricDefinitions": [ { "Name": "Train Loss", "Regex": "train_loss: (.*?);" }, { "Name": "Validation Loss", "Regex": "val_loss: (.*?);" }, { "Name": "Train Metrics", "Regex": "train_accuracy: (.*?);" }, { "Name": "Validation Metrics", "Regex": "val_accuracy: (.*?);" } ], "TrainingImage": "<アカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/sample:latest-gpu", "TrainingInputMode": "File" }, "EnableInterContainerTrafficEncryption": true, "EnableManagedSpotTraining": true, "Environment": { "PYTHON_ENV": "prod", "SAGEMAKER_PROGRAM": "/opt/program/train.py" }, "ExperimentConfig": { "ExperimentName": "prod-sample-experiment", "TrialName": "training-job", "TrialComponentDisplayName.$": "States.Format('{}', $$.Execution.Name)" }, "HyperParameters": { "max_length": "512", "learning_rate": "3e-5", "epochs": "5", "batch_size": "12" }, "CheckpointConfig": { "LocalPath": "/opt/ml/checkpoints/", "S3Uri": "s3://sample-prod-ml-data/workplace/model/checkpoints/" }, "InputDataConfig": [ { "ChannelName": "train", "DataSource": { "S3DataSource": { "S3DataDistributionType": "ShardedByS3Key", "S3DataType": "S3Prefix", "S3Uri": "s3://sample-prod-ml-data/workplace" } }, "InputMode": "File" } ], "OutputDataConfig": { "S3OutputPath": "s3://sample-prod-ml-data/workplace/model/" }, "ResourceConfig": { "InstanceCount": 1, "InstanceType": "ml.g4dn.xlarge", "VolumeSizeInGB": 10 }, "StoppingCondition": { "MaxRuntimeInSeconds": 86400, "MaxWaitTimeInSeconds": 86400 } }, "Catch": [ { "ErrorEquals": [ "States.ALL" ], "Next": "NotifySlackFailure" } ], "Next": "Experiments-Saving-Step" } RoleArn: S3, ECRにアクセスでき,SageMakerとStep Functionsのポリシーを持ったロールを指定する必要があります.エラーが発生した場合は適宜必要なポリシーをアタッチして下さい. MetricDefinitions: 学習時に出力しているログから正規表現を用いて結果をExperimentsに保存することができます.必要な評価指標をログ出力しておき,ここで取れるようにしておきます. TrainingImage: ECRに登録したdocker imageのURIを指定します.今回はGPU版のimageを用意してそれを使用しています. EnableManagedSpotTraining: trueを設定することでスポットインスタンスを使った学習が可能になります.ただし,CheckpointConfigを設定していないと状況次第で学習が停止し,また最初から始まってしまうので,注意が必要です. Environment: 環境変数を指定することができます.今回大事なのは,SAGEMAKER_PROGRAMの変数でここで指定したパスのスクリプトが実行されることになります. ExperimentConfig: SageMaker Experimentsに結果を保存する設定を行います.ExperimentNameとTrialNameは事前に作成しておく必要があります.(TrialNameとTrialComponentDisplayNameに関しては指定しない場合,自動的に適当な値が付与されますが,管理する上で把握しておく必要があります)今回はSageMaker Studioで事前に作成していますが,CreateExperimentやCreateTrialを使うことでStep Functionsの処理の1つとして実行することができます. HyperParameters: 学習時に使うハイパーパラメータや実験結果として残しておきたい値を入れておくことで保存されます. OutputDataConfig: 学習済みモデルを保存する場所になります.コンテナ内の’/opt/ml/model/'に保存されたモデルファイルがmodel.tar.gzとして圧縮された形で設定したパスに保存されます.これをモデルデプロイ時のモデルパスに指定する必要があります. ResultPathはTrainingJobの出力結果を後続の処理で使用したいので,nullの設定はしていません.その他の設定値はCreateTrainingJobを参考下さい.
CloudWatch Logsの結果を見ると,学習が実施できていることがわかります.これでTrainingJobを用いた学習を実施することができました.
モデル学習時のログ
SageMaker Experimentsの結果をS3に保存 学習後の実験結果はSageMaker Experimentsに保存されており,UI上だとSageMaker Studioからしか確認することができません.他のビジネス指標などと比較したい場合に毎回SageMaker Studioを見に行ったりすることは大変ですし,ダッシュボードなどで同時に見れることが望ましいです.コネヒトではBIツールとしてredashを使っているので,結果をcsvでS3に保存しておくとAthena経由でredash上で確認することができます.
モデル学習のステップの後に,実験結果の保存を行うステップを入れて対応しています.
upload_experiments.pyというスクリプト内で,SageMaker SDKを使用してsagemaker.analytics.ExperimentAnalyticsから記録した実験結果にアクセスして,必要な情報をデータフレームに整理して結果をcsvとしてS3にアップロードする流れになります.
SageMaker SDKを使用して実験結果を取得してみると,モデルの学習に要した時間が取得できなかったため上述したTrainingJobの出力結果をStep Functionsのステップで環境変数として渡すことで工夫しています.スクリプト内にos.environ['TRAINING_START_TIME']とos.environ['TRAINING_END_TIME']のような形で変数を受け取り終了時刻から開始時刻を引くことで経過時間を算出しています.この計算した値や学習した日付などの情報も合わせてデータフレームに記録するようにしています.
以下がTrainingJobの出力結果(不要な部分は一部削除しています)です.
{ "TrainingJobName": "4fc2550d-d694-3a8c-607a-368bbdd2a97d-Model-Training-Step", "ModelArtifacts": { "S3ModelArtifacts": "s3://sample-prod-ml-data/workplace/model/4fc2550d-d694-3a8c-607a-368bbdd2a97d-Model-Training-Step/output/model.tar.gz" }, "TrainingJobStatus": "Completed", "HyperParameters": { "batch_size": "12", "epochs": "5", "learning_rate": "3e-5", "max_length": "512" }, "InputDataConfig": [ { "ChannelName": "train", "DataSource": { "S3DataSource": { "S3DataType": "S3_PREFIX", "S3Uri": "s3://sample-prod-ml-data/workplace/", "S3DataDistributionType": "SHARDED_BY_S3_KEY" } }, "CompressionType": "NONE", "RecordWrapperType": "NONE" } ], "OutputDataConfig": { "S3OutputPath": "s3://sample-prod-ml-data/workplace/model/" }, "CreationTime": 1644856394459, "TrainingStartTime": 1644856580969, "TrainingEndTime": 1644873275331, "LastModifiedTime": 1644873275331, "SecondaryStatusTransitions": [ { "Status": "Starting", "StartTime": 1644856394459, "EndTime": 1644856580969, "StatusMessage": "Preparing the instances for training" }, { "Status": "Downloading", "StartTime": 1644856580969, "EndTime": 1644856654265, "StatusMessage": "Downloading input data" }, { "Status": "Training", "StartTime": 1644856654265, "EndTime": 1644873137479, "StatusMessage": "Training image download completed. Training in progress." }, { "Status": "Uploading", "StartTime": 1644873137479, "EndTime": 1644873275331, "StatusMessage": "Uploading generated training model" }, { "Status": "Completed", "StartTime": 1644873275331, "EndTime": 1644873275331, "StatusMessage": "Training job completed" } ] } Step Functionsの定義設定 - 実験結果の保存を行う処理 Step Functionsの定義設定は以下のようになっており,この処理はProcessingJobを使用しています.
"Experiments-Saving-Step": { "Type": "Task", "Resource": "arn:aws:states:::sagemaker:createProcessingJob.sync", "Parameters": { "AppSpecification": { "ImageUri": "<アカウントID>.dkr.ecr.ap-northeast-1.amazonaws.com/sample:latest-cpu", "ContainerEntrypoint": [ "python3", "/opt/program/upload_experiments.py" ] }, "Environment": { "PYTHON_ENV": "prod", "AWS_DEFAULT_REGION": "ap-northeast-1", "EXPERIMENT_NAME": "prod-sample-experiment", "TRIALS_NAME": "training-job", "TRIAL_COMPONENT_DISPLAY_NAME.$": "States.Format('{}', $$.Execution.Name)", "TRAINING_START_TIME.$": "States.Format('{}', $.TrainingStartTime)", "TRAINING_END_TIME.$": "States.Format('{}', $.TrainingEndTime)" }, "ProcessingResources": { "ClusterConfig": { "InstanceCount": 1, "InstanceType": "ml.t3.medium", "VolumeSizeInGB": 5 } }, "RoleArn": "arn:aws:iam::<アカウントID>:role/StepFunctions_SageMakerAPIExecutionRole", "ProcessingJobName.$": "States.Format('{}-{}', $$.Execution.Name, $$.State.Name)" }, "Catch": [ { "ErrorEquals": [ "States.ALL" ], "Next": "NotifySlackFailure" } ], "ResultPath": null, "Next": "Model-Creating-Step" } Environment: 環境変数に1つ前のTrainingJob(モデル学習ステップ)の出力結果であるTRAINING_START_TIMEとTRAINING_END_TIMEを参照して使用しています.これが先ほど説明した部分になります. 保存したcsvをデータフレームで表示する以下のような形になります.Trainingtimeとdatetimeが追加した部分になります.
S3に保存した実験結果のcsvファイル
おわりに 本エントリーの前編はモデル学習とその実験結果の保存に焦点を当てて紹介しました.Step FunctionsのSageMaker TrainingJobを使用したパイプライン構築を行った事例はほとんどないと思っているので,参考になれば嬉しいです.ちなみにSageMaker StudioのJupyter Notebookを使った手動実行の事例はいくつか存在していますし,公式のサンプルノートブックも多数あります.
今回の紹介した部分はMLOpsでいうところの「実験管理」や「パイプライン構築」にあたり,再現性や継続的な学習(Continuous Training)に繋がる部分になると思っています.
例えばパイプラインは,EventBridgeを使うことで定期的にモデルの更新を実施することが可能になりますし,モニタリングしている指標の変化を検知し,それをトリガーにしてモデルの更新を行うなどの方法も考えられます.
また,SageMaker Experimentsに実験結果を保存していくことでチームで結果を共有することができ,どういったパラメータでオフラインの評価指標がどうだったかなど知見として残し再現性を担保できるようになったのは大きな前進かなと思います.
一方で,TrainingJobを使う点において少し辛い点を書くと以下が挙げられます.
デバッグがしんどい 実行時間がそれなりにかかる 動作確認するためにStep Functionsで処理を組んで実行すると起動するまでに時間がかかるのと,コード変更が入った時に毎回ECRにイメージをpushしてから再実行となるので,デバッグするのに一苦労かかります.そもそもエラーが分かりづらいという部分もありますが...笑
後編では,作成したモデルのデプロイと推論を行うためのエンドポイントのデプロイの部分について紹介します.
最後に,コネヒトではプロダクトを成長させたいMLエンジニアを募集しています!!(切実に募集しています!)
もっと話を聞いてみたい方や,少しでも興味を持たれた方は,ぜひ一度カジュアルにお話させてもらえると嬉しいです.(僕宛@asteriamにTwitterDM経由でご連絡いただいてもOKです!)
www.wantedly.com
コネヒトの機械学習プロジェクトにおける構想フェーズ・PoCフェーズの進め方
コネヒト
2022-03-23 10:30:25
みなさんこんにちは。機械学習チームのたかぱい(@takapy0210)です。
最近はワールドトリガーというアニメにハマっておりまして、2022年から第3期の放映が始まっております。
内容はよくあるバトルアニメですが、チームで戦略を練って戦うところがユニークでとても面白いです。(個々の力だけだと到底叶わない相手に対して戦略で勝つ、という展開もあり、戦略の大事さを改めて痛感しました)
さて本日は、コネヒトの機械学習プロジェクトがどのように推進され、開発・実装フェーズに移行していくのかについて、1つの事例を交えながらご紹介できればと思います。(※あくまで1つの事例なので、全てがこのように進むわけではありません)
目次
今回のプロジェクト概要 機械学習プロジェクト全体の流れ 構想フェーズ:ビジネス要件を明確にし、共通認識をつくる どんな効果を期待しているのか?(ROI的な話) PoCフェーズ:定量チェックと定性チェックの両方を実施する 定性チェックの必要性 で、今回の施策の効果はどうだったの? We are hiring!! 今回のプロジェクト概要 コネヒトではママリというコミュニティアプリを運営しており、1ヶ月で約130万件のQAが投稿されています。
この投稿を全て目視チェックするのは現実的に不可能なため、目視チェックする前段で機械学習モデルによるチェックを挟むことで、荒らしのような投稿やガイドラインに違反するような投稿のみを、人間がチェックする運用となっております。
(詳細は以前のブログでも紹介しているので、興味のある方はこちらもご覧ください)
今回のプロジェクトは、この検閲モデルを特定のユーザークラスタに適応し運用させることで、CS(カスタマーサクセス)チームの抱える課題を解決できるのではないか、ということでスタートしています。
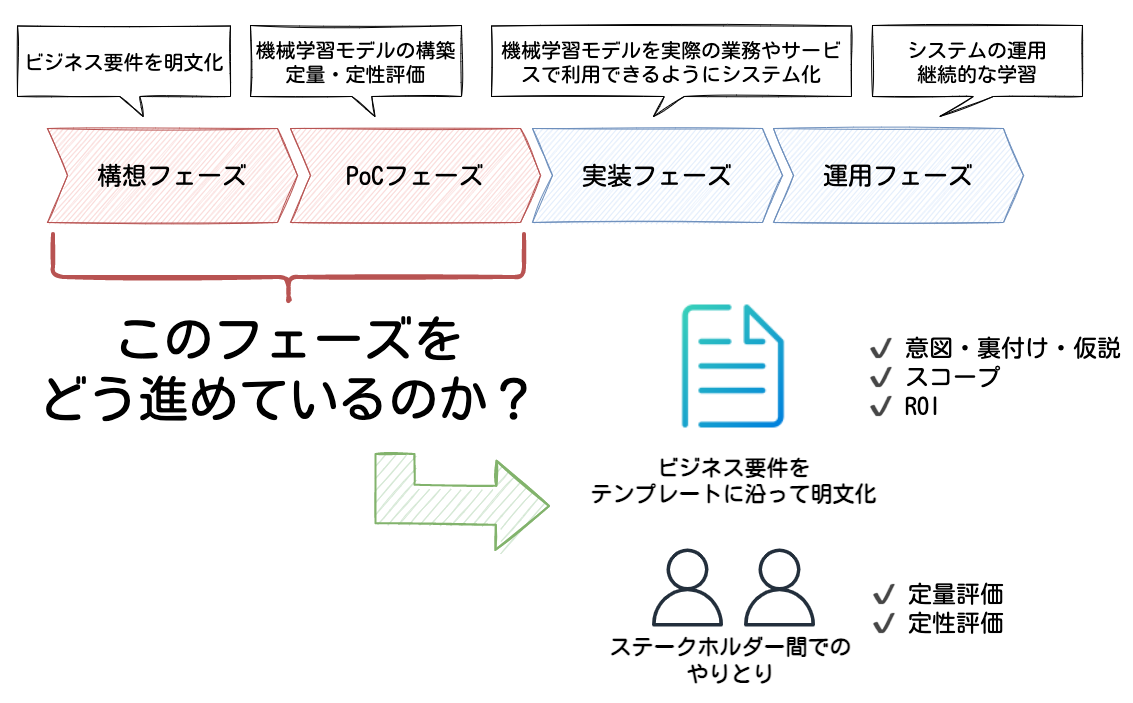
機械学習プロジェクト全体の流れ 機械学習プロジェクトには、大きく分けて以下4つのフェーズがあると考えています。
構想フェーズ PoCフェーズ 実装フェーズ 運用フェーズ 本エントリでは、構想フェーズとPoCフェーズに焦点を当てながらお話ししていこうと思います。
それぞれのフェーズを簡単に説明すると、構想フェーズではプロジェクトによって解くべき課題を特定し、ビジネス要件を明文化していきます。ここでは、十分に投資対効果が見込まれるテーマを見極めることが重要だと思います。
PoCフェーズでは、構想フェーズで立てたテーマが技術的に実現可能かどうかを、機械学習モデルのモックアップを構築して検証していきます。
上記のフェーズで特に大切だと感じている点について、プロジェクトの事例を交えながら深ぼってお話ししていこうと思います。
構想フェーズ:ビジネス要件を明確にし、共通認識をつくる PoCフェーズ:定性チェックと定量チェックの両方を実施する 構想フェーズ:ビジネス要件を明確にし、共通認識をつくる 今回は以下のようなテンプレートに沿って、CSチームと共に要件を明文化していきました。
※ 冒頭でもお話した通り「既に本番で運用している検閲モデルを特定のユーザークラスタでも扱えるよう適応させる」というプロジェクトなので、本来であれば議論すべきである「機械学習で扱えるテーマかどうか」について、今回は議論していません。
# 提案施策の概要(3行くらいで) - hoge - fuga - piyo ## 関連する部門や人 - hoge ## 要求分解 - As is:今何が起きているか(今(まで)、こうだ(った)よね、みたいな話) - hoge - Issue:その状況をどう捉えているか、何が課題か(これって問題だよね、みたいな話) - hoge - To be:あるべき姿・なりたい姿 / どんなアプローチで解決するのか(なので〜というアプローチをして〜のような状態になりたい、みたいな話) - hoge # アプローチの具体(As is → To beになるための具体的な行動) ## (To beに対して)なぜそのアプローチ・解決策なのか?(意図・裏付け・仮説) - hoge ## 今回は具体的に何をしようとしているのか?(今回のスコープ) - hoge ## どんな効果を期待しているのか?(ROI的な話) - hoge 上記の項目を全て埋めることができれば、自然と全体像が見えてくるようになると思います。
中でも個人的には「どんな効果を期待しているのか?(ROI的な話)」の部分が重要だと思っているので、次項でもう少し詳しくお話しします。
どんな効果を期待しているのか?(ROI的な話) ここで考えることは、ざっくり言うと「今までは〇〇だったものが、この施策をやることで×××になる」といったことになります。
今回のプロジェクトでは具体的に以下のようなことについて議論し明文化しました。
- コスト削減 - 定量評価:検閲件数が半分削減できたときにxx万円/月カット - サービス品質向上 - 定量評価:人間が目視検査しなくて良いものはすぐに投稿されるので、回答率の向上や回答がつくまでの時間が短縮できる - サービス品質維持 - 定性評価:検閲モデルを導入したあとでもコミュニティの品質は担保したい - etc... このように、定量的な数値に関しても関係者間で共有認識をとっておくことで、この後のPoCフェーズがスムーズにいくと思います。
今回の例では「検閲件数が半分に削減できれば月のオペレーション時間がxx時間ほど削減できる」ということが試算できているので、「コミュニティの品質を維持しながら、検閲件数が従来の半分に削減できる機械学習モデル」を開発すれば良いことになり、PoCフェーズのゴールもある程度明確にすることができます。
(最高のモデルを開発すべく奮闘し、気がついたらずっとPoCやっている・・・みたいなことも防げます😇 )
ビジネス要件が明文化され、ビジネスインパクトが大きいと判断できれば、次のPoCフェーズへ移行します。
PoCフェーズ:定量チェックと定性チェックの両方を実施する 今回の機械学習モデルは「ガイドラインに違反しているか否か」を判別するシンプルな2値分類タスクです。
このようなタスクで用いられる評価指標としてはAccuracyやRecall、Precisionなどが挙げられ、これらの指標を用いて構築した機械学習モデルの性能を定量的に評価していきます。
ある程度形になってきたら、実際の運用を想定すべく、ある一定期間のデータをモデルで推論したものを、CSチームに定性的に評価してもらいます。
ここでチェックしてもらう目的は以下の2点です。
コミュニティ運営の視点から、ガイドラインに著しく違反しているものが正しく推論できているか モデルの閾値*1をどの程度にすれば、期待する成果( = コミュニティの品質を維持しつつ、検閲件数を従来の半分にする)を実現できそうか 定性チェックの必要性 定量的な評価のタイミングでは、例えば「Recallが80%(今回だと、違反と推論したデータの中に真の違反データがどれくれい含まれているか)」という値は計算することができますが、この数値だけで本来の要件であった「コミュニティの品質を維持しつつ、検閲件数を従来の半分にする」が満たせるかどうか判断するのは難しいです。
「取りこぼしている20%にはどのようなデータが含まれているのか?」「20%のうち漏らしたくないデータを漏れなく検閲するには、どのような方法が考えられるか?」といった部分を議論できるように、CSチームにチェックしてもらいつつビジネス要件との差分を徐々に詰めていきます。
この議論により、「機械学習モデルをアップデートして精度を上げれば解消できそうな問題」なのか、それとも「モデルのアップデートでは解消できない問題なので、後処理などを工夫する必要がある」のか、といった勘所を掴むこともできます。
上記のようなモデル構築→定量チェック→定性チェックを繰り返しながら、当初の要件を満たせるところまで、検証を続けていきます。
今回はベースラインモデル(ver1)を作成してCSチームに定性チェックをお願いしたところ、検閲漏れの投稿(人間の目視チェックを行いたいが、モデルでは"問題なし"と推論されたデータ)がいくつかあったため、そこを解消できるようにモデルをアップデート(ver2)しました。
ver2のモデルでは定性チェックも問題なかったため、実装フェーズに移行し、2022/03/23現在では無事に運用できています。
実際にCSチームに定性チェックをお願いした時のやりとり
で、今回の施策の効果はどうだったの? 運用を開始してまもなく1ヶ月ほど経ちますが、当初の期待通り、xx万円/月のコスト削減に寄与できています。
また、1つの質問に対する平均回答数も0.3ほど向上しており、コミュニティにとっても良い影響を及ぼすことができました。
We are hiring!! コネヒトでは、プロダクトを成長させたいMLエンジニアを募集しています!!(切実に募集しています!)
ライフイベント、ライフスタイルの課題解決をするサービスに興味がある方 機械学習の社会実装、プロダクト開発に興味のある方 是非お話できれば嬉しいです!
カジュアル面談では答えられる範囲でなんでも答えます!(特に準備はいりません!)
自分のTwitter宛てにDM送っていただいてもOKですし、下記リンクからお気軽にご連絡お待ちしています!
www.wantedly.com 大規模データを活用してサービスの成長にコミットする機械学習エンジニア募集! by コネヒト株式会社
*1:今回のモデルは違反確率を出力するものになっているので、閾値を決める必要があります
PHPStanを0.11から1.4へメジャーアップデートした際の知見
コネヒト
2022-03-22 06:34:27
こんにちは!webエンジニアの高谷です。
弊社ではCakePHPなどの社内のプロジェクトで使われているフレームワークやライブラリのアップデートを定期的に行っています。
その一環でママリのアプリ内で使用されているwebviewのCakePHPを3.8から4.0にアップデートした際に、使用しているPHPStanのバージョンが0.11とかなり古めだったのでこちらも1.4にメジャーアップデートしました。
今回はPHPStanを中心にアップデートした際の変更点をいくつかピックアップしていきたいと思います。
はじめに PHPStan1.0のリリース PHPStanは最初のリリース(2016年7月)から長らく0系でしたが去年の2021年11月に1.0がリリースされました。
1.0では静的検査をする際の新しいレベルの登場や破壊的変更がいくつかありますが詳しくは公式サイトからご覧ください。
phpstan.org
アップデートによる変更点 bin-pluginを削除して同一のcomposer.jsonで管理する。 bin-pluginについてはこちらに詳しく纏まっていますが簡単に説明すると、ライブラリの依存パッケージのバージョンが他のライブラリの依存パッケージとコンフリクトを起こしていた場合に任意の名前空間でcomposer.jsonやcomposer.lockを分けてコンフリクトを解消しようというものです。
(こんな感じにディレクトリを分けて管理することが出来ます)
以前のバージョンのPHPStanでは依存パッケージのバージョンが他のライブラリとコンフリクトを起こしていたのでbin-pluginを使用して別々で管理するようにしていました。 ですが0.12からPharファイルでの配布が公式採用されて依存パッケージのコンフリクトが起きないようになったので同一のcomposer.jsonで管理するようにしました。
phpstan.org
CakeDC/cakephp-phpstanの導入 CakeDC/cakephp-phpstanはCakePHP4系専用のPHPStanの拡張ライブラリです。
PHPStanは独自のルールを追加する為のカスタムルールや特定のクラスの__get、__setなどのマジックメソッドの引数や戻り値を静的検査できるようにする拡張機能があり、その拡張機能を利用した拡張ライブラリが豊富に配布されています。
CakePHP4系に上げてCakeDC/cakephp-phpstanを導入する事によってCakePHP独自の設定をそちらに委任するようにしました。
github.com
phpstan.neonの修正 phpstan.neonはPHPStanの設定ファイルの事で、静的検査の対象/除外したいディレクトリの設定や無視したいエラーなど他にも様々な設定を記述する事によってそのプロジェクトにあった柔軟な設定が実現できます。
1系になった事で設定ファイルの項目名の破壊的変更がありautoload_filesやbootstrapの項目が削除されたりしましたが公式ドキュメントに従って修正すれば特に難しい事はありませんでした。
phpstan.org
まとめ 今回は特にPHPStanのメジャーアップデート起因による大きな修正は無かったですが、これからも継続的にメンテナンスをしていき快適な静的検査を実施していきたいと思います。
このブログでは他のメンバーのCakePHP4系や周辺ライブラリのバージョンアップに関する記事があるのでぜひそちらもご覧ください!
「こんなところも?」 CakePHP4・phpunitのアップグレードに伴う変更箇所 - コネヒト開発者ブログ
CakePHP3から4へのバージョンアップ時に困ったキャッシュ周りの話 - コネヒト開発者ブログ
Android版ママリアプリのリファクタ事情 ~時刻テスト編~
コネヒト
2022-03-18 05:36:18
こんにちは。2017年11月にAndroidエンジニアとしてjoinした@katsutomuです。
前回のエントリーから、髪の毛はアップデートされておりません。そろそろ予定を立てないとな〜と思いつつ、重い腰が上がりません。
さて今回は、時刻テストに関するリファクタリングについて紹介いたします。
はじめに コネヒト社で開発しているママリ Android 版は、開発が始まってから 5 年以上経過しました。
開発当初からの歴史の中で、さまざまなコードを継ぎ足してきたママリ Android 版は、いくつもの改善ポイントを抱えています。この記事では、ようやくメスを入れられた 「現在時刻に関係したユニットテストの基盤づくり」 の取り組みを紹介します。
前提 io.kotest v4.6.3 背景 現在時刻に関係したユニットテストのやり方についてググれば、ユニットテスト実行時に現在時刻を固定するサンプルコードは色々ありますが、今回は io.kotest と組み合わせて、少し書きやすくしてみます。
実装 現在時刻を提供するクラス まずは現在時刻を提供するクラスです。 現状、まだ移行が完了していないため org.threeten.bp.XXX を使っていますが java.time.XXX でも同じです。
import androidx.annotation.VisibleForTesting import org.threeten.bp.Clock import org.threeten.bp.Instant import org.threeten.bp.LocalDate import org.threeten.bp.LocalDateTime import org.threeten.bp.ZoneId import org.threeten.bp.ZonedDateTime /** * 現在時刻を提供するクラス */ object CurrentTimeProvider { private val systemClock = Clock.systemDefaultZone() private var currentClock: Clock = systemClock fun currentZoneId(): ZoneId = currentClock.zone fun toLocalDate(): LocalDate = LocalDate.now(currentClock) fun toLocalDateTime(): LocalDateTime = LocalDateTime.now(currentClock) fun toZonedDateTime(): ZonedDateTime = ZonedDateTime.now(currentClock) fun toInstant(): Instant = currentClock.instant() fun toMillis(): Long = currentClock.millis() @VisibleForTesting object Test { const val DEFAULT_YEAR = 2000 const val DEFAULT_MONTH = 1 const val DEFAULT_DAY_OF_MONTH = 1 const val DEFAULT_HOUR = 0 const val DEFAULT_MINUTE = 0 const val DEFAULT_SECOND = 0 const val DEFAULT_NANO_OF_SECOND = 0 /** * 現在時刻を固定する。 */ fun fixed( year: Int = DEFAULT_YEAR, month: Int = DEFAULT_MONTH, dayOfMonth: Int = DEFAULT_DAY_OF_MONTH, hour: Int = DEFAULT_HOUR, minute: Int = DEFAULT_MINUTE, second: Int = DEFAULT_SECOND, nanoOfSecond: Int = DEFAULT_NANO_OF_SECOND, zoneId: ZoneId = ZoneId.of("Asia/Tokyo"), ) { val fixedInstant = ZonedDateTime .of( year, month, dayOfMonth, hour, minute, second, nanoOfSecond, zoneId, ) .toInstant() currentClock = Clock.fixed(fixedInstant, zoneId) } /** * 現在時刻を固定する。 */ fun fixed(time: ZonedDateTime) { currentClock = Clock.fixed(time.toInstant(), time.zone) } /** * 現在時刻を固定する。 */ fun fixed(instant: Instant) { currentClock = Clock.fixed(instant, currentZoneId()) } /** * 現在時刻の固定を解除する。 */ fun tick() { currentClock = systemClock } } } 現在時刻を固定する拡張関数 今回は io.kotest.core.spec.style.ExpectSpec を対象にしています。 実際のテストコードは test: suspend TestContext.() -> Unit で実行し、その実行前後で現在時刻の固定と解除をします。
import io.kotest.core.spec.style.scopes.ExpectSpecContainerContext import io.kotest.core.test.TestContext suspend fun ExpectSpecContainerContext.expectOnFixedTime( name: String, year: Int = CurrentTimeProvider.Test.DEFAULT_YEAR, month: Int = CurrentTimeProvider.Test.DEFAULT_MONTH, dayOfMonth: Int = CurrentTimeProvider.Test.DEFAULT_DAY_OF_MONTH, hour: Int = CurrentTimeProvider.Test.DEFAULT_HOUR, minute: Int = CurrentTimeProvider.Test.DEFAULT_MINUTE, second: Int = CurrentTimeProvider.Test.DEFAULT_SECOND, nanoOfSecond: Int = CurrentTimeProvider.Test.DEFAULT_NANO_OF_SECOND, test: suspend TestContext.() -> Unit, ): ExpectSpecContainerContext { CurrentTimeProvider.Test.fixed(year, month, dayOfMonth, hour, minute, second, nanoOfSecond) expect(name, test) CurrentTimeProvider.Test.tick() return this } 実際に現在時刻を固定したテスト ExpectSpecContainerContext に対して定義した拡張関数 expectOnFixedTime() を使います。固定したい時刻を引数で指定します。
ExpectSpecContainerContext#expect(...) と近いインターフェースにしておいたので、同じような使い方で書けるようになりました。
class ExpectSpecExtensionTest : ExpectSpec({ context("current time") { val expectFixedYear = 1987 val expectFixedMonth = 3 val expectFixedDayOfMonth = 30 expectOnFixedTime("fixed", year = expectFixedYear, month = expectFixedMonth, expectFixedDayOfMonth) { CurrentTimeProvider.toZonedDateTime().apply { year shouldBe expectFixedYear month.value shouldBe expectFixedMonth dayOfMonth shouldBe expectFixedDayOfMonth } } } おわりに 今回は、現在時刻に関係したユニットテストの基盤づくりの一例を紹介しました。 今後も継続的に改善を進めていく予定です。最後までお読みいただきありがとうございました!
今回の改修を主導してくれた、もっさん*1に感謝します!!
PR コネヒトでは、バリバリとリファクタリングを進めてくれるAndroidエンジニアを募集中です!
hrmos.co
*1:業務委託で参画してくれている水元さんです
Sass から styled-components に移行している話
コネヒト
2022-03-18 03:04:55
こんにちは!エンジニアの富田です。 今回はママリのアプリ内で使われている WebView の Sass を一部 styled-components へ移行しましたので、その事例を紹介します。
特に真新しい情報はありませんが、1つの事例として読んでいただければ幸いです。
はじめに ママリのアプリ内の WebView の背景を説明すると、2020/07 以前に作られた画面は Sass x FLOCSS で作成されました。それ以降の新規作成する画面については、styled-components を使用して作成されており、Sass と styled-components が混在する状態になっています。
少しずつではありますが、WebView クライアントの健全性を高めるべく、Sass を利用しているいくつかの画面を styled-components 化しましたので、移行の流れを紹介します。
移行の流れ 移行する画面を決める Sass から styled-components へ置き換え 動作確認 移行する画面を決める 今回はプロダクト開発の空き時間を利用して移行するため、全てを Sass から styled-components 化するには作業量が多く、あまり現実的ではありませんでした。従って、移行する画面をいくつかピックアップしたのですが、それほど使われていない画面を移行してもあまり意味がないため、よく利用されている画面を styled-components 化することに決めました。
Sass から styled-components へ置き換え 移行する画面を決めたらあとは愚直に Sass から styled-components へ置き換えていきます。対象画面の Sass のスタイルを styled-components に書き換えていく中で、ママリのカラーパレットに準拠していないカラーコードが散見されたため、適切なカラーコードを利用するように整理しました。
また、Cypress によるスクリーンショットの比較テストが導入されているため、コミットしてプッシュするたびに CI 上で UI が崩れていないか自動チェックしてくれるので、安心しながら効率的に移行を進めていました。
コンポーネント単位で上記を繰り返していくことで、置き換えが完了します。
動作確認 いよいよ動作確認です。正常な動作を確認し、CI のテストが通っていれば、最後に実機で動作確認します。
この段階で特に問題は見つからず、Cypress による自動チェックの恩恵を受けて効率的に移行できました。
おわりに 今回は Sass から一部 styled-components 化した事例を紹介させてもらいました。まだまだ一部なので、引き続き移行は続けていきたいと思います。また Cypress の自動テストのおかげで効率よく作業を進められ、テストの重要性を改めて感じました。
引き続き、ママリのモダン化を進めていきたいと思います。
PR コネヒトでは、フロントエンド開発のモダン化に挑戦したいエンジニアも募集中です!
hrmos.co
Canvas を使って画像をリサイズする
コネヒト
2022-03-18 12:38:12
はじめに こんにちは! フロントエンドエンジニアの もりや です。
今回はママリのアプリ内で使われている WebView で、画像をリサイズする処理を Canvas で実装した事例を紹介します。
画像のリサイズが必要な理由 昨今のスマホのカメラで撮った画像は数MB程度と大きく、アップロードに時間がかかったり、そもそもサーバー側で何MBまでの画像を許容するかなど課題もあります。 また iOS/Android のママリアプリでも、おそらく同様の理由からリサイズをしてアップロードするようになっていました。 そのため、WebView でもアップロード前に画像をリサイズする処理を入れ、快適かつ安全にアップロードできるようにしました。
ライブラリなどもあると思いますが、今回のようにシンプルなリサイズ用途であれば Canvas のみで十分可能と判断し実装してみました。
Canvas とは Canvas API は JavaScript と HTML の <canvas> 要素によってグラフィックを描く方法を提供します。他にも、アニメーション、ゲームのグラフィック、データの可視化、写真加工、リアルタイム動画処理などに使用することができます。 https://developer.mozilla.org/ja/docs/Web/API/Canvas_API
つまり、グラフィックに関する様々なことができる Web API です。
サポートされているブラウザも96%以上とかなり多く、ほとんどの環境で使えると思います。
https://caniuse.com/canvas
Canvas を使ったリサイズの実装 今回実装したリサイズ処理を、実装例を使いながら解説します。 (コード全体を見たい場合は「コード例」の章まで飛ばしてください)
なお、今回はコードをシンプルにするため幅 (width) だけを指定してリサイズするような処理にしています。
1. Context の取得 Canvas に描画するために必要な CanvasRenderingContext2D を取得します。
const context = document.createElement('canvas').getContext('2d') ちなみに 2d の他に webgl, webgl2, bitmaprenderer といった値も指定できるようです。 (私は使用したことがないので、説明は省略します)
2. 画像サイズの取得 リサイズ後のサイズを計算するために、Image を使用して変換対象の画像のサイズを取得します。
const image: HTMLImageElement = await new Promise((resolve, reject) => { const image = new Image() image.addEventListener('load', () => resolve(image)) image.addEventListener('error', reject) image.src = URL.createObjectURL(imageData) }) const { naturalHeight: beforeHeight, naturalWidth: beforeWidth } = image console.log("H%ixW%i", beforeHeight, beforeWidth) // => H800xW600 画像のロード後でしかサイズが取得できないので、コールバックを使いつつ Promise でラップするような感じにしています。
ちなみに new Image() で引数を指定しない場合は、naturalHeight, naturalWidth でも height, width でも同じ値になるようです。
CSS pixels are reflected through the properties HTMLImageElement.naturalWidth and HTMLImageElement.naturalHeight. If no size is specified in the constructor both pairs of properties have the same values.
https://developer.mozilla.org/en-US/docs/Web/API/HTMLImageElement/Image#usage_note
3. 変換後のサイズを計算 今回は幅 (width) のみを指定する方法にしているので、比率を保ちつつリサイズできる高さを計算して出します。
const afterWidth: number = width const afterHeight: number = Math.floor(beforeHeight * (afterWidth / beforeWidth)) 4. Canvas にリサイズ後のサイズで画像を描画 まず Canvas のサイズをリサイズ後の大きさにします。
context.canvas.width = afterWidth context.canvas.height = afterHeight そして、画像をキャンバス上に描画します。
context.drawImage(image, 0, 0, beforeWidth, beforeHeight, 0, 0, afterWidth, afterHeight) 引数を9個指定した場合は、以下のような内容になります。
ctx.drawImage(image, sx, sy, sWidth, sHeight, dx, dy, dWidth, dHeight);
https://developer.mozilla.org/en-US/docs/Web/API/CanvasRenderingContext2D/drawImage
元画像のデータ (image) 元画像データの描画開始座標 (sx, sy) 元画像のサイズ(sWidth, sHeight) キャンバスへの描画開始座標 (dx, dy) キャンバスへの描画サイズ (dWidth, dHeight) という感じになります。 元画像全体を、キャンバスのサイズピッタリに描画するというような意味合いになります。 これが実質リサイズ処理になります。
5. Canvas の内容を JPEG で出力 最後に Canvas の内容をJPEGとして出力します。
const jpegData = await new Promise((resolve) => { context.canvas.toBlob(resolve, `image/jpeg`, 0.9) }) こちらもコールバックしか使えないので、Promise でラップするような感じにしています。
ちなみに image/jpeg 以外にも image/png や image/webp なども使えるようです。
コード例 これらのコードをまとめた関数の実装例を紹介します。 (ママリで実際に使っているコードと全く同じではないので悪しからず)
export const resizeImage = async (imageData: Blob, width: number): Promise<Blob | null> => { try { const context = document.createElement('canvas').getContext('2d') if (context == null) { return null } // 画像のサイズを取得 const image: HTMLImageElement = await new Promise((resolve, reject) => { const image = new Image() image.addEventListener('load', () => resolve(image)) image.addEventListener('error', reject) image.src = URL.createObjectURL(imageData) }) const { naturalHeight: beforeHeight, naturalWidth: beforeWidth } = image // 変換後の高さと幅を算出 const afterWidth: number = width const afterHeight: number = Math.floor(beforeHeight * (afterWidth / beforeWidth)) // Canvas 上に描画 context.canvas.width = afterWidth context.canvas.height = afterHeight context.drawImage(image, 0, 0, beforeWidth, beforeHeight, 0, 0, afterWidth, afterHeight) // JPEGデータにして返す return await new Promise((resolve) => { context.canvas.toBlob(resolve, `image/jpeg`, 0.9) }) } catch (err) { console.error(err) return null } } サンプルページ 上記のコードを使って、簡単に試せるページを用意してみましたので、興味がある方はお試しください。
https://mryhryki.com/experiemt/resize-on-canvas.html
(猫画像はこちらのフリー素材を使用しました) https://pixabay.com/ja/photos/%e7%8c%ab-%e8%8a%b1-%e5%ad%90%e7%8c%ab-%e7%9f%b3-%e3%83%9a%e3%83%83%e3%83%88-2536662/
おわりに ブラウザの機能だけをつかって、シンプルに画像のリサイズ処理を実装することができました。 実は、個人的に Skitch の代替として使っている Web App を作った経験が生きた感じで、割とすんなりと実装ができました。 なんでも色々やって見るものですね。
PR コネヒトではエンジニアを募集しています!
hrmos.co
AWS OpenSearchでの技術検証をスムーズにしたTIPS
コネヒト
2022-03-18 12:25:40
こんにちは。インフラエンジニアの永井(shnagai)です
今回は3ヶ月ほど行っていたAWS OpenSearchの技術検証をしている中で、技術検証のスピードアップに貢献してくれたTIPSを2つご紹介出来ればと思います。
内容はざっくり下記2項目です。
ユーザ辞書やシノニムOpenSearchのカスタムパッケージを使って管理する Reindex APIを使ったIndex変更内容の反映高速化 ユーザ辞書やシノニムOpenSearchのカスタムパッケージを使って管理する カスタム辞書と日本語全文検索 今回、日本語の全文検索を行うための技術検証でOpenSearchを触りました。
全文検索を行うにあたっては、ユーザ辞書やシノニム、ストップワードの設定が肝になります。
例えば、OpenSearchで使える日本語の形態素解析エンジンであるkuromojiを使って文章を分割するケースを考えてみます。
ユーザ辞書を使わないプレーンなkuromojiの解析結果が下記です。
抱っこ/紐/と/朝/ごはん/を/食べる/こと
抱っこ紐が「抱っこ」と「紐」に分割されているので、このままだと「抱っこ紐」と全文検索した時にこの文章のスコアは高くなりません。(厳密に言うとsearch時にどう単語を分割して当てにいくかの話だがここでは単純なパターンを想定して話します)
「抱っこ紐」と検索したら、「抱っこ紐」の情報が一番に出てきてほしいので、ユーザ辞書で「抱っこ紐」を定義したインデックスを作ります。
tst_custom_dicというカスタム辞書を使ったインデックスのサンプル
PUT tst_custom_dic { "settings": { "index": { "analysis": { "tokenizer": { "kuromoji_user_dict": { "type": "kuromoji_tokenizer", "user_dictionary_rules": [ "抱っこ紐,抱っこ紐,ダッコヒモ,カスタム名詞" ] } }, "analyzer": { "tst_analyzer": { "type": "custom", "tokenizer": "kuromoji_user_dict" } } } } } } user_dictionary_rules 部分でカスタム辞書を定義し、インデックスを再作成することで下記のように「抱っこ紐」を一単語として分割することが可能になります。
抱っこ紐/と/朝/ごはん/を/食べる/こと
カスタムパッケージを利用してインデックスを定義 先程説明した形は、インデックスのtokenizerの定義で辞書を管理する方法なのですが、カスタム辞書は何百、何千というワードを登録するためインデックスの定義で辞書を管理すると本質的ではない部分で定義が冗長になり可読性や保守性が著しく下がってしまいます。
このような課題を解決するために、OpenSearchではs3に保存したカスタム辞書ファイルを使える機能がカスタムパッケージという名前で提供されています。 シノニムとストップワードも同じ方法で外部ファイル化が可能です。
詳細な設定方法は、下記の公式ブログで詳しく解説されているのでこちらをご覧ください。
https://docs.aws.amazon.com/ja_jp/opensearch-service/latest/developerguide/custom-packages.html
カスタムパッケージを使う際のインデックスの定義は下記のようになります。
PUT tst_custom_dic { "settings": { "index": { "analysis": { "tokenizer": { "kuromoji_user_dict": { "type": "kuromoji_tokenizer", "user_dictionary": "analyzers/F72444002" } }, "analyzer": { "tst_analyzer": { "type": "custom", "tokenizer": "kuromoji_user_dict" } } } } } } tokenizer内の user_dictionary に analyzers/パッケージID を指定することで利用可能になります。
カスタムパッケージを使うことで、辞書更新が下記のようなフローで可能になります。
カスタム辞書を手元のエディタで追加 s3にファイルをアップロード OpenSearchのカスタムパッケージ機能で2のファイルをインポート 新しいversionが付与される 辞書更新をしたいOpenSearchクラスタで「更新を適用」するとパッケージが最新になる(5分くらいかかるがその間は前のverを使える) 同じカスタムパッケージを利用していても、クラスタ単位で適用タイミングをずらせるので、stgで先にカスタム辞書を更新して動作確認してから、本番にも適用するというようなフローを組むことも出来ます。 インデックスを更新(Reindexもしくは作り直し)することで新たなカスタム辞書でトークン分割されたインデックスを利用可能に Reindexについては、この後紹介します エイリアス更新するかインデックス名を変えて参照元からの参照先を変えるか この辺はまだ設計途上 今考えているデプロイパターンだと、
2のs3アップロードをGitHubマージトリガで動かして、3以降はs3のputトリガでStepFunctionsを動かすも良し、CIツールでAWS SDK使ったフロー組むのも良しという形で自由度高く組めると考えています。
まだ、その部分の検証はしていないので手を動かしながら最適解を探していきたいと思います。
最後に、もっとこうなるとうれしいと思った部分を一つだけ
パッケージの更新時にバリデーション走ると尚うれしい 現状だと辞書の内容の間違いに気づくのは、openSearchのインデックスを更新するタイミングでのエラーで気づく 只、自動適用考える時にCI側でバリデーションするのがフローとしては健全と思っている(この部分はまだ未検証) Reindex APIを使ったIndex変更内容の反映高速化 OpenSearch(Elasticsearchでも一緒)では辞書の更新はもちろん、インデックス自体の定義を更新するには、インデックス自体を新規で作り直す必要があります。
これはインデックスの作成時に、定義に基づいてトークン化が行われるからです。
検証中は特に、インデックスの定義を更新して、データがどう変わるかを見るというオペレーションが頻発します。
ストレートにこのインデックス更新を行うと、下記手順を繰り返します。
定義の更新 元のインデックスの削除 DELETE Index インデックスの新規作成 PUT Index ~BodyにJSONの定義 新規のインデックスにデータを投入 あまりにも非効率だなと思い、色々と調べるとelastic社の公式ドキュメントにReindexというAPIが紹介されていることを発見しました。
https://www.elastic.co/guide/en/elasticsearch/reference/7.6/docs-reindex.html
下記のような簡単なAPIを叩くことで、インデックスのコピーが出来ることを発見しました。
量により処理時間はマチマチですがbulkでデータ投入するよりは圧倒的に早いです。
POST _reindex { "source": { "index": "元のインデックス名" }, "dest": { "index": "新しいインデックス名" } } このReindexを使うようになったことで技術検証のスピードは圧倒的に早くなりました。(始めから気づけよという話ではあるのですが。。)
Reindexを使った本格的な運用について、二三歩先に進んだ事例も下記のブログで紹介されています。 https://tech.legalforce.co.jp/entry/2021/12/21/190129
今回はOpenSearch(Elasticsearch)の運用に役立ちそうなTIPSを2つ紹介しました。
次回はもう少し踏み込んだ内容の日本語の形態素解析でハマったことを中心に書こうと思います。
コネヒトではサービスの信頼性向上をミッションに幅広い領域をカバーしながらエンジニアリングの力でサービスをよりよくしていけるエンジニアを募集しています。 少しでも興味もたれた方は、是非気軽にお話出来るとうれしいです。
サービスファーストな思考ができるインフラエンジニア募集! | コネヒト株式会社
iOS/Android と WebView でデータを連携する仕組みを作りました
コネヒト
2022-03-17 12:44:22
はじめに こんにちは! フロントエンドエンジニアの もりや です。
今回は、ママリアプリ内で iOS/Android と WebView 間でデータを連携する仕組みを作った事例を紹介します。 2021年6月頃に実装してリリースし、現在(2022年3月)も問題なく使えています。
データの連携を使いたい場面 ママリの場合、例えば以下のような場面で使っています。
【WebView → iOS/Android の例】 WebView で作った入力画面で編集中の時に、閉じるボタンを押した場合は iOS/Android 側で確認ダイアログを出す 【iOS/Android → WebView の例】 iOS/Android 側で処理を行った後で、WebView 側で何らかのアクションを行いたい場合 それまではその場その場で対応していましたが、これらを共通で便利に扱うための仕組みをそろそろ作りたいね、という話がでてきたので実装をしました。
JavaScript (TypeScript) での実装方法 WebView → iOS/Android の連携 この場合は window.mamariq.state という名前空間を用意して、iOS/Android からそこを参照してもらう形にしました。
window.mamariq = { state: { PAGE: { // ページごとに名前空間を作る KEY: VALUE, // 参照してもらいたい値を入れる } } } 状態が変わったら、その値を更新していきます。 React の場合は、以下のように useEffect で更新するようにする実装が多いです。
useEffect(() => { window.mamariq.PAGE.KEY = value }, [value]) あとは iOS/Android から必要な時にセットされている値を見にいけばOKです。
(iOS/Android での実装方法は「iOS/Android からの呼び出し方」の章を参照してください)
補足1: WebView からプッシュしたい場合 上記の方法は、状態を参照して処理するタイミングが iOS/Android 側で決めるものなので、すぐに iOS/Android へ状態を伝えたい場合には使えません。 そういった用途は(ページ遷移を伴わない)専用のディープリンクを作って対応しています。
補足2: iOS の一般的なやり方 ちなみに iOS でプッシュする場合あれば、以下のやり方が一般的だそうです(yanamura からお聞きしました)
【Swift】WKWebViewでJavaScriptのコールバックを受けつける(WKUserContentControllerの使い方)
ただ、このやり方だと iOS と Android で方式を変えないといけないので、共通で使えるやり方を考えました。
iOS/Android → WebView の連携 この場合は window.mamariq.action という関数を用意しておき、iOS/Android から呼び出してもらう形にしました。 また、UI側では必要なシーンでリスナーを登録しておき、イベントの内容に応じて処理を登録する、という形にしています。
ざっくりと以下のような構造になっています。
+-----------------------+ | iOS/Android | +-----------------------+ | | イベント発行 v +-----------------------+ | window.mamariq.action | +-----------------------+ | | イベント発行 v +-----------------------+ | listeners | +-----------------------+ ^ | 登録/削除 | | イベント発行 | v +-----------------------+ | UI (React) | +-----------------------+ リスナーの管理・登録・削除 リスナーは以下のような型定義になっています。 type というイベントを識別するキーと、必要な場合は(iOS/Android 側で)payload に情報を詰めて呼び出してくれます。
// リスナーに渡されるイベントの型定義 export interface MamariqBridgeEvent { type: string payload: ObjectType } // リスナーの型定義 type MamariqBridgeEventListener = (event: MamariqBridgeEvent) => void リスナーを管理する配列と、それに追加・削除をするための関数を用意しておきます。
// リスナーを管理する配列 let listeners: MamariqBridgeEventListener[] = [] // リスナーを削除する関数 export const removeMamariqEventListener = (listener: MamariqBridgeEventListener): void => { listeners = listeners.filter((_listene) => _listener !== listener) } // リスナーを追加する関数 export const addMamariqEventListener = (listener: MamariqBridgeEventListener): void => { removeMamariqEventListener(listener) // 重複登録を避けるため、念の為一度削除する(通常は何も起こらない) listeners.push(listener) } window.mamariq.action iOS/Android からイベントを受け取るための関数を定義しておきます。
window.mamariq = { action: (event: unknown): void => { const type = `${checkObject(event).type ?? '(unknown)'}` const payload = checkObject(checkObject(event).payload) ?? {} listeners.forEach((listener) => listener({ type, payload })) } } checkObject はオブジェクト型であるかを確認して、違う型であっても必ずオブジェクト型で返してくれる関数です。
type ObjectType = { [key: string]: unknown } const checkObject = (target: unknown): ObjectType => { if (typeof target === 'object' && target != null && !Array.isArray(target)) { return target as ObjectType } return {} } React からのリスナーの登録・削除 実際に使用する側では、useEffect を使ってこういう感じで実装してます。
useEffect(() => { const receiveMamariqBridgeEvent = (event: MamariqBridgeEvent): void => { switch (event.type) { case 'EVENT_TYPE': // do something break } } addMamariqEventListener(receiveMamariqBridgeEvent) return () => removeMamariqEventListener(receiveMamariqBridgeEvent) }, []) そのコンテキストで必要なイベントのみハンドリングするようにしておくことで、リスナーを複数登録したり新しいイベントを追加した場合でも問題が起きにくくしています。
この実装のメリット iOS/Android で同じ形でできることが一つのメリットかな、と思います。
また DevTools のコンソールを使って、実機を繋がなくてもブラウザ単体で動作確認ができるのも一つのメリットだと思います。 (他の方法はあまり知りませんので、推測です)
// 現状のステートを確認できる console.log(window.mamariq.state.PAGE.KEY) // iOS/Android からイベントが来た場合の動作を確認できる window.mamariq.action({ event: "EVENT_TYPE"}) ハマったところ iOS で boolean が数値扱いされる iOS の場合、boolean値 (true, false) が何故か 0, 1 の数値として取得できてしまうとのことでした。 その原因はわかりません・・・。 (知っている方いましたらコメントいただけると嬉しいです)
今回は、それぞれ文字列 ("true", "false") とすることで対応しました。
iOS/Android からの呼び出し方 yanamura と tommykw にご協力頂き、それぞれの OS での実装箇所を抜粋しました。
iOS での呼び出し方 状態の読み取り window.mamariq.xxx のデータを以下のように取得します。
webView .evaluateJavaScript( "window.mamariq.xxx" ) { [weak self] result, _ in if let result = result as? String, result == "true" { // do something } else { // do something } } イベントの発行 window.mamariq.action() で以下のようにイベントを発行します。
let params: [String: Any] = [ "type": "xxx", "payload": [ "yyy": "zzz" ], ] do { let data = try JSONSerialization.data(withJSONObject: params, options: []) guard let stringValue = String(data: data, encoding: .utf8) else { assertionFailure() return } contentViewController.webView.evaluateJavaScript( "window.mamariq.action(\(stringValue))" ) { _, _ in } } catch { // do something } Android での呼び出し方 状態の読み取り window.mamariq.xxx のデータを以下のように取得します。
// データバインディングを利用 binding.webView.evaluateJavascript("window.mamariq.xxx") { result -> if (result == "true") { // do something } else { // do something } } イベントの発行 window.mamariq.action() で以下のようにイベントを発行します。
// データバインディングを利用 binding.webView.evaluateJavascript("window.mamariq.action({type:'xxx'})") {} おわりに 既に実装して8ヶ月以上が経ち、本番環境でも使っていますが、現状では特に問題なく使えています。 やっていることがシンプルなので、あまり不具合が起きにくいというのもあるかもしれません。
この仕組みを作っておいたおかげで、iOS/Android と WebView でデータを連携する時に実装方法に迷うことがなくなり、実装に集中できるようになりました。 最初が少し面倒ですが、早めにやっておくとコスト的にペイできたな〜、と思っています。
PR コネヒトではエンジニアを募集しています!
hrmos.co
1年間プロダクトゴールを運用していく中で行った3つの工夫
コネヒト
2022-03-14 06:02:54
こんにちは。バックエンドエンジニアのTOCです。
弊社ではミッションごとにいくつかチームに分かれており、それぞれのチームでスクラム開発を行なっています。 (弊社開発体制についてはこちらの記事に詳しく記載があります) 今回は僕が所属しているチームで去年から運用しているプロダクトゴールについて、運用するにあたって、どういった工夫をしているのかを書きたいと思います。
※当エントリーでは「プロダクトゴールとは何か」という点については言及しませんが、同じチームの方が共有してくれたブログにプロダクトゴールの例が記されているので、もしよければ参考にしていただければと思います。
Product Goal & Sprint Goals – A Simple Example
目次
プロダクトゴールを運用するようになった背景 プロダクトゴールを運用するために行なってる3つの工夫 1. 日常的に振り返る 2. 定期的に振り返る 3. 達成を諦めないアイデア会 おわりに プロダクトゴールを運用するようになった背景 僕が所属するチームでは、スクラムガイドが改訂になったタイミングでスクラムガイドの理解を深める会を行いました。この会ではスクラムガイド2020解説ビデオをみんなで鑑賞した後に、それぞれが感想や疑問に思ったことを出し合い議論することを行いました。
(一人で黙々と読んでも理解が深まりづらい僕にとって、こういった場があるのは非常にありがたいです🙌 )
この会の中で、プロダクトゴールってなんなの?という疑問が議論の中心になり、チームで深ぼってみる価値がありそうだ、ということで継続してプロダクトゴールについて考えようということになりました。
何度かプロダクトゴールについて話し合い、チームとしてプロダクトゴールを実際に作って試してみよう!ということで自分たちなりに解釈をし、作成したプロダクトゴールを運用してみることに決定しました。
プロダクトゴールを運用するために行なってる3つの工夫 運用することが決まってから、半期ごとにプロダクトゴールを設定し、日々開発を行なっているのですが、運用する上で行なっている工夫について3つご紹介したいと思います。
1. 日常的に振り返る プロダクトゴールを設定したはいいものの、ただ設定しただけでは自分達って何を目指しているんだっけ?というような状態になり、目の前のことに追われてしまいかねません。 そこで、自分達が達成したいゴールを意識しながら開発ができるように日常的にプロダクトゴールを目にする機会を作るようにしています。
具体的にはデイリースクラムやレトロスペクティブなど、日々行なっているスクラムイベントのタイムラインにプロダクトゴールを確認する時間を設けるようにしています。
例えばデイリースクラム時は先日リリースした機能がプロダクトゴールにどう寄与しているのかをPdMから共有してもらったりしています。 また、デイリースクラムの進行表にはプロダクトゴールを一番上に書いてるので、日々目に入ってプロダクトゴールがチームの合言葉みたいな感じになりました💪
ちょっとした工夫で盛り上がりながらチームで運用できているので、継続して振り返ることができています!
2. 定期的に振り返る 日常的にプロダクトゴールの振り返りを行なっていますが、時には深い議論をしたり、「本当に達成できるのか」「達成するためにできることはないのか」といったちょっとした時間ではできない議論をしたくなったりします。 なので月に一回、「プロダクトゴールの現状確認と振り返り」という会を1時間半かけて行なっています。 この会はモデレーターをチームで交代制にしていて、それぞれが考えた流れで進行していきます。モデレーターが毎回変わるので、今までにいろんな会が行われました!
プロダクトゴールを眺めてKPTをやってみる プロダクトゴールの達成ができそうかをグラフ化してみる プロダクトゴール達成に向けて勢いづけるためにウィンセッションしてみる チームメンバーが考えたワークを行なって、日々の仕事とプロダクトゴールの関係性を考えてみる 達成できそうかの表明や、ウィンセッションの様子
メンバーの個性が出るので、今回はどんな感じなんだろうと毎月ワクワクしています!
実際に運用してみると、計画通りにいかないこともあるので、一回立ち止まって考える機会を設けると日々の変化に対応した運用ができるかなと思っています。
3. 達成を諦めないアイデア会 2.でも記載したように、プロダクトゴール達成のための計画を遂行していく中で、やってみて初めてわかることだったり、思うようにいかなかったりすることはあるかと思います。結果を見た上で、もっとこういうことできるんじゃない?というような具体的な施策案を思いついたとしても、あまりチームで案出しをして話し合える機会って意外とない、という意見があったので、プロダクトゴールを達成するためのアイデア出し会を最近行いました。 やり方としてはアイデアをブレストしてからインパクトと工数の2軸でマッピングをして、それを元にPdMの方がブラッシュアップした施策案リストをNotionに作成してくれます。
出てきたアイデアをマッピング 施策案リスト
実際に行ってみると、プロダクトゴール設定時には出てこなかったアイデアだったり、最近リリースした機能を応用して少ない工数でできそうなアイデアが出てきて、非常に有用な会になりました。
チーム内でも、こういった機会は定期的にあっても良さそう、という話になり、隔週くらいのペースで時間をとってみることをトライしています。 この取り組みは最近始めたばかりなので、まだ試行錯誤中ですが、ブラッシュアップしていきながら、より有用なものにしていきたいと思っています!
おわりに 以上がプロダクトゴールを運用するにあたってチーム内で行なっている工夫になります。 日々運用する中で、チーム内で「これってこのままでいいんだっけ?」「もっと良くできるんじゃない?」といったアイデアが出てくるのが素敵だなぁと思いながら、運用方法をブラッシュアップしています! 今回紹介した内容が、何かしら日々の開発に役立つようなことがあれば幸いです。
コネヒトでは、各チームで様々な工夫を行い日々スクラム開発を進めています。 今回のような活動に少しでも興味をもたれた方は、ぜひ一度お話させてもらえるとうれしいです。
hrmos.co
Android版ママリアプリのリファクタ事情 ~パッケージ構成編~
コネヒト
2022-03-11 10:38:58
こんにちは。2017年11月にAndroidエンジニアとしてjoinした@katsutomuです。
前回のエントリーから、髪の毛はアップデートされておりません。そろそろ髪の毛切りに行ってさっぱりと4月を迎えたいと思っています!
さて今回は、パッケージ構成のリファクタリングについて紹介いたします。
初めに コネヒト社で開発しているママリ Android 版は、開発が始まってから 5 年以上経過しました。
開発当初からの歴史の中で、さまざまなコードを継ぎ足してきたママリ Android 版は、いくつもの改善ポイントを抱えています。この記事では、ようやくメスを入れられた 「目的のコードにたどり着くまでに時間がかかる」 という問題への取り組みを紹介します。
結論 まず、問題へ取り組んだ結果を紹介します。
対応としては、パッケージの構成を変更しました。 以下の画像は、ママリ Android 版の今までのパッケージ構成です。
そして、改善後のパッケージ構成がこちらです。
なぜ問題が発生してたか 「目的のコードにたどり着くまでに時間がかかる」 という問題が起こっていた理由を考察したところ、「ある機能を実現しているコードがまとまっていないから」という話になりました。
普段のプロダクト開発では、新規機能の開発もありますが、すでに実装している機能に対しての改修も頻繁に行われています。
その機能を実現している既存のコードが、複数のパッケージに分散している、同じロジックなのに複数箇所に分散している、などまとまっていない状態になっていた場合、まず分散している箇所の把握から始める必要があり、その知識があった上で改修を行う必要があります。
日々開発している我々が「この機能のコードがどこにあるのか」というのを常に覚えられているか、というと、人によってはなかなか難しいことと感じることもあります。思い出す時間や探す時間が少しばかり必要になることもあり、そこにパワーを割けなくてもよいならそれに越したことはないですね。
改修内容 コードをまとめる、にしてもいろいろな観点がありますが、まずパッケージを見直すことを最初の一手としてメスを入れました。
今までのパッケージ構成は以下の通りでした。
この構成で発生していた問題は、例えばある機能を構築するクラス FooActivity FooFragment FooAdapter FooViewModel があった場合、パッケージレベルで分散しているので、これらのクラスを探すことに無駄なパワーを割く必要がありました。
- .activity - FooActivity - .adapter - FooAdapter 改修後のパッケージは以下の通りです。
この構成にのっとると以下のような配置になります。 こうすることで、ある画面への改修をするときに、この .foo パッケージさえ知っていれば探す手間も省けます。またパッケージの命名は、普段の業務中の会話で使われている言葉を流用することで、より直感的なコードに近くなるのも良いです。
- .foo - FooActivity - FooAdapter おわりに 今回は、なかなか手をつけられていなかったパッケージ構成の改善について紹介させていただきました。今後も継続的に改善を進めていく予定です。最後までお読みいただきありがとうございました!
今回の改修を主導してくれた、もっさん*1に感謝します!!
PR コネヒトでは、バリバリとリファクタリングを進めてくれるAndroidエンジニアを募集中です!
hrmos.co
*1:業務委託で参画してくれている水元さんです
Google オプティマイズのリダイレクトテストを使ってABテストを実施する
コネヒト
2022-03-11 06:08:12
こんにちは。 @otukutunです。 今回とあるキャンペーンサイトでGoogle オプティマイズのリダイレクトテストとCakePHPを連携して、すばやくABテストできる仕組みを構築したのでその方法について説明します。
Google オプティマイズとは Google オプティマイズはGoogleが提供しているABテストツールで、無料で提供されています(2022/03/11時点)。Google製ということもあり、Googleアナリティクス連携がスムーズにできる使い勝手のよいツールです。Google オプティマイズには様々なテスト方法が提供されていて、A/B テストやサーバーサイドテスト、リダイレクトテストなど様々な方法(エクスペリエンス)が提供されています。
各方法の具体的な説明はこちらの公式ページに見ていただくといいですが、ざっくりと説明すると
A/B テストはHTMLや画像などのクライアントサイドの要素をテストできる、各種variantの振り分けはGoogleオプティマイズに任せることができる サーバーサイドテストはサーバーサイド側の要素もテストできる、ただし各種variantは自前でする必要がある(サーバーサイドテストの詳細はこちら) リダイレクトテストはランディングページ(以下LP)のテストができる、各種variantの振り分けはGoogleオプティマイズで行われ、ランディング後にリダイレクトされる になっています。
サーバーサイドの変更をテストする場合は、サーバーサイドテストとリダイレクトテストが候補として上がりましたが、今回はリダイレクトテストを選択して行いました。理由としてはいくつかあるんですが
今回の対象がキャンペーンサイトでLPは1つになるので、リダイレクトテストでも要件を満たせた(サーバーサイドテストである必要がなかった) リダイレクトテストではVariantの比率などをwebページから操作できるので柔軟に設定できる(後から比率を変更することもできます)。サーバーサイドテストではサーバー側で実装する必要がある 結果が分かった段階で、一旦成果がでたvariantに寄せることができる Google Optimizeの設定が実装依存が少ないのでシンプルになる などの利点があり、リダイレクトテストにしました。
リダイレクトテストを実施する リダイレクトテストと連携するために
LPでvariantを表すクエリストリングストリングからvariant設定する variantを取得する機能を提供(切り替えのため) (任意) 完了ページでURLでクエリストリングを付与する を実装して連携できるようにしました。実装例はCakePHPですが、他の言語やフレームワークでも同じような実装でできるかと思います。
オプティマイズの設定 a
パターンでLPのvariantごとのURLを設定し、ページターゲティングを設定するだけです(目標数値などの設定は今回のテーマではないので省略します)。
CakePHPの実装 実装はシンプルでLPでクエリパラメータをみてvariantを設定して、それによって挙動を変えてあげるだけです。endページではクエリパラメータをつけることでどのvariantかをGAだけでなく広告のコンバージョンタグでも判別が容易になるようにしています。
CampaignsController.php
<?php class CampaignsController extends AppController { public function lp() { // ABテスト開始 $this->startABTest(); // variant毎に処理を変える if ($this->getABTestVariant() === 'a') { // オリジナルの場合 } else if ($this->getABTestVariant() === 'b') { // variant Bの場合 } // variantをクエリストリングに付与する $this->redirect('controller' => 'Campaings', 'action' => 'end', '_method' => 'GET', ['?' => ['variant' => $this->request->getSession()->read('ab_test_session')]]); } public function end() { // クエリストリングにvariantが付与される } /** * ABテストのタイプを設定 */ private function startABTest() { // 設定済みの値 $current = $this->getRequest()->getSession()->read('ab_test_session'); $variant = $this->request->getQuery('variant'); if (!in_array($variant, ['a', 'b'])) { // クエリパラメーターなしの場合は既に設定されている値、それもない場合はaとする $userType = $current ?? 'a'; } $this->getRequest()->getSession()->write( 'ab_test_session', $userType ); } } Viewで挙動を変えたい場合はこんな感じで、切り分ければいけます。
lp.ctp
<?php // variantを取得 $abTestVariant = $this->request->getSession()->read('ab_test_session') ?> <?php if ($abTestVariant === 'a'): ?> <p>Aだよ~</p> <?php elseif ($abTestVariant === 'b'): ?> <p>Bだよ~</p> <?php endif; ?> おわりに Google オプティマイズのリダイレクトテストと簡単な仕組みでvariantの振り分けは任せつつvariant毎の実装に集中できるようになりました。今はComponentとHelper化してさらに使いやすくなり、素早くABテストを行えるようになっています。何かの参考になれば幸いです。ではまた!
HimotokiからSwift.Decodableに徐々に移行させる
コネヒト
2022-03-11 02:40:15
こんにちは!コネヒトでiOSエンジニアをやっていますyanamuraです。
コネヒトではAPIで取得したJSONをDecodeするのにHimotokiを使ってきましたが、Swift4でSwift.Decodableが追加されてからは新しいコードはSwift.Decodableを使っています。共存状態はのぞましくなく全てSwift.Decodableにしたいところですが、かなりの量があるので一気に変更するのが大変で影響範囲も大きいです。そのため、徐々に移行していく方針を取りました。
ステップ1 徐々に移行するためにまずAPI通信部分のユニットテストを用意しました。古いAPI周りはテストが書かれていなかったのでちょっと大変でしたが、これをしたことで変更に凡ミスが入らないという安心感がえられ、また、置き換え作業自体もコンパイルとテストが通っていれば実機で動かして確認する必要がなく効率的に行うことができました。
ステップ2 ここからHimotoki.DecodableをSwift.Decodableに置き換えていきます。
置き換える上で問題となってくるのが、以下の例のようにDecodableなstruct間で依存が発生しているパターンです。
struct Question: Himotoki.Decodable { let user: User // UserもHimotoki.Decodable let answers: [Answer] // AnswerもHimotoki.Decodable } struct Video: Himotoki.Decodable { let user: User let videoId: Int } QuestionをSwift.Decodableにしようとすると、その子のUser, AnswerもSwift.Decodableにしなければならず、さらにUserがSwift.Decodableに変えると、それを使っているVideoもSwift.Decodableに変える・・というように芋づる式に変更が必要となり大変なことになります。
そこでこのような場合は、次のようなパターンで対応していきます。
case1: 親がない場合 Swift.Decodableに変更するだけでOK
case2: 親が一つしかない場合 子:Swift.Decodableに変更
親:
before
extension DailyMessageResponse: Himotoki.Decodable { static func decode(_ e: Extractor) throws -> DailyMessageResponse { return try DailyMessageContent( dailyMessage: e <| "daily_message", child: e <| "child" ) } } after
// daily_messageだけSwift.Decodableにする extension DailyMessageResponse: Himotoki.Decodable { static func decode(_ e: Extractor) throws -> DailyMessageResponse { let decoder = JSONDecoder() decoder.dateDecodingStrategy = .iso8601 decoder.keyDecodingStrategy = .convertFromSnakeCase if let json = e.rawValue as? [String: Any], let dailyMessageJSON = json["daily_message"] { let dailyMessage = try decoder.decode(DailyMessage.self, from: try JSONSerialization.data(withJSONObject: dailyMessageJSON, options: [])) return try DailyMessageContent( dailyMessage: dailyMessage, child: e <| "child" ) } else { throw Himotoki.DecodeError.missingKeyPath("daily_message") } } } case3: 親が複数ある場合 子:Himotoki.Decodable, Swift.Decodable両方に準拠する
extension User: Himotoki.Decodable { static func decode(_ e: Extractor) throws -> User { return try User( id: e <| "id", name: e <| "name" ) } } extension User: Swift.Decodable {} 親:
親はすぐに変更しなくても問題ない。
親を変更する場合は、親が1つのパターンを使って一つずつ変更する。
まとめ これを地道に続けてると移行が完了します。
コネヒトで開発しているママリiOSアプリではようやく移行が完了し、トータルで20~30個くらいのPullRequestになりました。移行完了までかなり時間を要しましたが、コネヒトでは2週間に一日くらいの頻度で、丸一日は普段開発しているプロダクトの目標とは関係のない負債解消などの技術的なことを行うようにしていまして、これを活用してやりきることができました。
大規模な変更となりましたが、問題なく移行完了しました。1つだけリグレッションテストで不具合が見つかりヒヤリとしましたが、その不具合は唯一ユニットテストの書き漏れがあった箇所のコードで発生しておりユニットテストの重要さを改めて感じました。
コネヒトではこういった負債解消だけでなくSwiftUIの導入など技術的なチャレンジも盛り込みながら開発しています。もしご興味ありましたら一度話を聞きに来てください!
hrmos.co
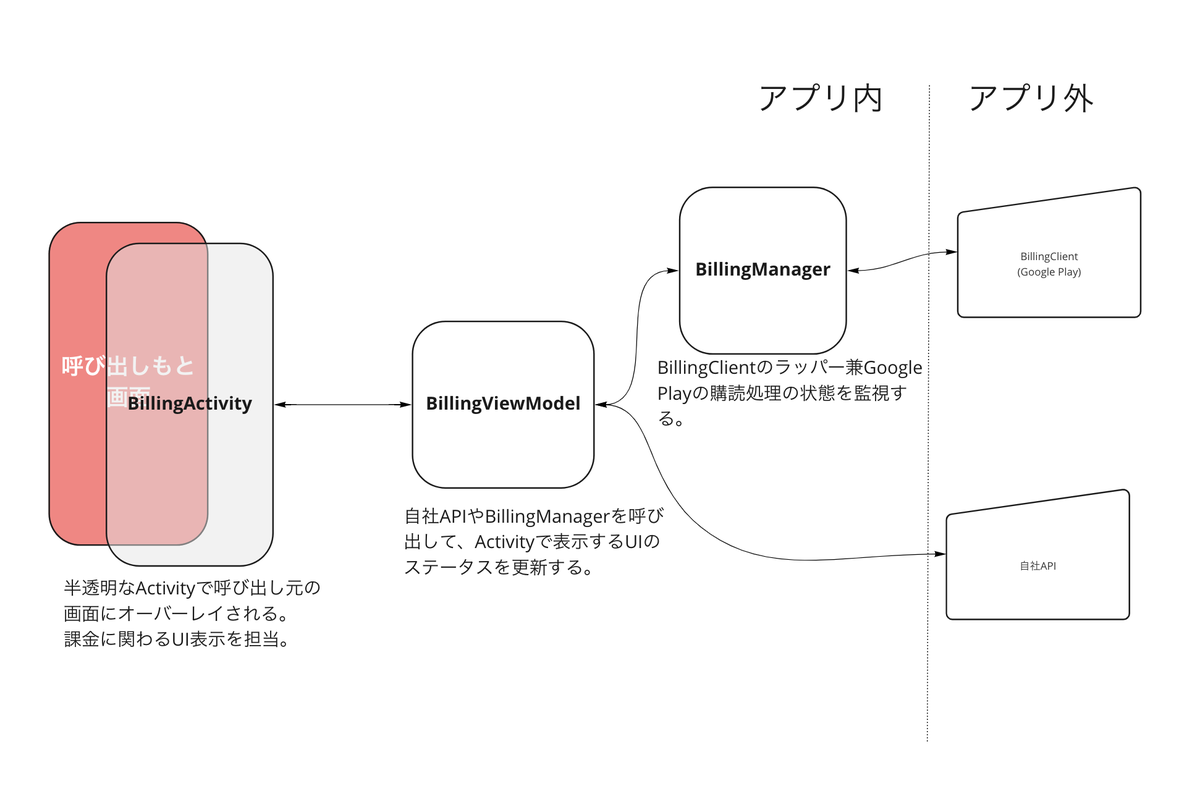
Android版ママリアプリのリファクタ事情 ~ Google Play Billing Library 4導入編 ~
コネヒト
2022-03-04 10:10:25
こんにちは。2017年11月にAndroidエンジニアとしてjoinした@katsutomuです。前回のエントリーから、髪の毛はアップデートされておりません。
さて今回は、Android版ママリアプリの課金機能にまつわるお話をお伝えできればと思います。
はじめに 2021 年 11 月 1 日にGoogle Playのアップデートにより、アプリ内課金機能ライブラリの Billing Library で v3 以降が必須となりました。
Google Play Billing Library のバージョンのサポート終了 | Google Play の課金システム | Android Developers
ママリアプリではアプリ内課金の定期購入機能で、プレミアムサービスを提供していますが、Billing Library v2に依存していたため、期日までにライブラリのアップデートをする必要がありました。 今回は、BillingLibrary v4の紹介をしつつ、ライブラリのアップデート時の課金機能のリファクタリングの事例を紹介します。
Billing Library v4の紹介 まず初めにアプリ内課金を実装するための、最新のライブラリであるBilling Library v4の使い方をを紹介をします。
接続と破棄 アプリ内課金機能を利用するには、Google Playと接続し課金処理を実行する必要があるため、まずはその準備が必要となります。
BillingClientを生成し、Google Playに接続を行います。課金アイテムの取得、購入/リストアといった課金操作は、基本的にBilingClientのメソッドを使用します。また接続を残し続けると、メモリリークが発生するため、不要になったら破棄が必要になります。
// BillingClientの生成 private val billingClient by lazy { BillingClient.newBuilder(context) .setListener(object : PurchasesUpdatedListener { override fun onPurchasesUpdated(result: BillingResult, list: MutableList<Purchase>?) { // 課金状態が更新されると呼び出される。 } }) .enablePendingPurchases() .build() } // Google Playに接続し、課金機能の呼び出し準備をする fun initialize() { billingClient.startConnection(object : BillingClientStateListener { override fun onBillingServiceDisconnected() { // 切断が切れたら呼び出される。必要に応じて再接続処理など } override fun onBillingSetupFinished(result: BillingResult) { // 初期化が完了すると呼び出される。ここが呼ばれないと課金処理が始められない。 } }) } // 不要になったら接続を切る fun release() { billingClient.endConnection() } 課金情報の取得 課金を開始する前に、現在の課金状態を確認する必要がある場合、queryPurchasesAsyncメソッドを利用して現在の課金情報を取得します。
queryPurchasesAsyncメソッドは、Google Playから現時点の課金情報をリクエストします。 契約が存在する場合、Purchaseクラスのリストが返却されるので、Purchaseクラスが提供する購読情報を参照することができます。
private fun queryPurchases() { billingClient.queryPurchasesAsync( BillingClient.SkuType.SUBS // 課金種別の指定 ) { result, list -> val responseCode = result.responseCode if (responseCode == BillingClient.BillingResponseCode.OK) { // 成功の場合は、Purchase型がリストで返される } else { // OK以外はエラー } } } ママリアプリでは、重複課金を防ぐために、現在の課金情報を取得してバリデーションを行なっています。
課金履歴の取得 過去の課金履歴が必要な場合は、queryPurchaseHistoryAsyncメソッドを呼び出します。購入の有効期限が切れていたり、キャンセルされていても、最後に購入した購読情報が返却されます。
billingClient.queryPurchaseHistoryAsync( BillingClient.SkuType.SUBS ) { result, list -> val responseCode = result.responseCode if (responseCode == BillingClient.BillingResponseCode.OK) { // 成功の場合は、PurchaseHistoryRecordがリストで返される } else { // OK以外はエラー } } ママリアプリでは、過去の課金状態に応じて、ユーザーにお得なキャンペーンを訴求することをしています。
課金処理の実行 実際に課金を行うためには、2つの作業が必要になります。
購読に必要なSkuDetailsを取得する SkuDetailsを元に課金処理を起動する このクラスをlaunchBillingFlowメソッドに渡すことで、課金処理が開始されます。画面操作を伴うためか、activityを渡す必要があります。
※SkuDetailsには課金アイテムの名称や価格の情報が含まれているため、ユーザーに見せるために使うことも可能です。
var skuDetails: List<SkuDetails> = emptyList() private fun querySkuDetails() { val params = SkuDetailsParams.newBuilder() .setType(BillingClient.SkuType.SUBS) .setSkusList(listOf(itemType.id)) // 課金アイテムのIDリスト .build() billingClient.querySkuDetailsAsync(params) { result, list -> val responseCode = result.responseCode if (responseCode == BillingClient.BillingResponseCode.OK) { skuDetails = list // 成功するとSkuDetailsがリストで返される。このリストを元に購読処理を起動。 } else { } } } private fun launchBilling() { val builder = BillingFlowParams.newBuilder() builder.setSkuDetails(skuDetails).build() // 購読処理にはactivityが必要 billingClient.launchBillingFlow(activity, builder.build()) } リファクタリングの方向性 冒頭で書いた通りママリアプリではv2に依存したライブラリで、定期購読の機能を実現していましたが、複数の画面や機能から購読機能を利用したいというビジネス要件や自社APIやBillingClientとの連携でステータスを管理する必要があるといった技術的な制約を実現するために、既存のコードは非常にファットな状態でした。今回はv4への置き換えと並行して課金ロジックのリファクタリングも進めていました。
これらの事情を踏まえて、最終的にBillingActivity、BillingViewModel、BillingManagerの3つのクラスに責務を分離した設計となりました。
処理の流れは以下の通りです。
プレミアム会員登録画面で、課金ボタンをタップするとBillingActivityが起動する 半透明なActivityなため元の画面にオーバーレイされる ActivityのonCreateをトリガーにBillingViewModelがBillingManagerを呼び出しGooglePlayの課金処理を開始する BillingManagerでBillingClientのメソッドを呼び出しGoogle Playの課金処理を開始する BillingManagerが結果を元にBillingViewModelが自社APIをコール、ステータスに応じて、BillingActivityのUIを更新する それぞれの役割と処理の流れをソースコードと合わせて紹介します。
BillingManager
このクラスはGooglePlayの課金機能を呼び出すことと、BillingClientの結果を元にしたステータス管理を担当しています。課金機能の初期化の成否や、Google Playの操作、課金結果の待ち受けなど複数の状態を監視する必要があるため、RxJavaのCombineLatestを利用し、複数の状態を集約してステータスを更新しています。
処理の流れは以下の通りです。
BillingClientとの接続と現在の課金情報の取得を開始 Activityを引渡し、GooglePlay課金の開始 Google Play課金のステータス監視。最後まで成功したら社内APIを呼び出すステータスに移行する // 1. BillingClientとの接続と現在の課金情報の取得を開始 fun initialize(billingType: BillingType) { billingClient.startConnection(object : BillingClientStateListener { override fun onBillingSetupFinished(billingResult: BillingResult) { val responseCode = billingResult.responseCode if (responseCode == BillingClient.BillingResponseCode.OK) { when (billingType) { is BillingType.Purchase, BillingType.Restore -> { querySkuDetails() queryPurchases() } } } } }) } ・・・・・ // 2. Activityを引渡し、GooglePlay課金の開始 fun doSubscribe(activity: AppCompatActivity, readyToPurchased: ReadyToPurchased) { val type = readyToPurchased.billingType val builder = BillingFlowParams.newBuilder() builder.setSubscriptionUpdateParams( BillingFlowParams.SubscriptionUpdateParams.newBuilder() .setOldSkuPurchaseToken(readyToPurchased.purchases[0].purchaseToken) .build() ) builder.setSkuDetails(readyToPurchased.skuDetails).build() billingClient.launchBillingFlow(activity, builder.build()) _purchasing.onNext(true) } ・・・・・ // 3. Google Play課金のステータス監視。最後まで成功したら社内APIを呼び出すステータスに移行する Observables.combineLatest( _initialized, // 課金手続き準備完了のステータスの監視 _purchasing, // 課金手続き中ステータスの監視 _billingResult // 課金結果の監視 ) { initializeStatus, purchasing, billingResult -> var nextStatus = _status.value when (_status.value) { ・・・・・ is ReadyToPurchased -> { nextStatus = // 一度Activityに準備完了を通して、課金手続き中ステータスに移行 } is Purchasing -> { nextStatus = // 課金完了後に社内APIのコールを行うReadyToRegisterのステータスに移行 } } _status.onNext(nextStatus) }.subscribe().addTo(compositeDisposable) BillingViewModel
このクラスはGooglePlayの課金処理の呼び出し社内APIの登録と、その間の状態変化をActivityに伝える責務を担当しています。処理の流れは以下の通りです。
BillingManagerの初期化完了を待ち、課金機能の開始を指示する. BillingManagerのステータスを監視し、UI表示をActivityに通知する。 GooglePlay課金完了後、社内APIに課金情報を送信し、ユーザーをプレミアム会員に昇格する。 @OnLifecycleEvent(Lifecycle.Event.ON_CREATE) fun onCreate() { billingManager.status.distinctUntilChanged().subscribe { status -> when (status) { // 1. BillingManagerの初期化完了を待ち、課金機能の開始を指示する is BillingManger.ReadyToPurchased -> { startPurchase.postValue(status) } // 3. GooglePlay課金完了後、社内APIに課金情報を送信し、ユーザーをプレミアム会員に昇格する。 is BillingManger.ReadyToRegister -> { registerReceipt(status.purchasedData) } } // 2. BillingManagerのステータスを監視し、UI表示をActivitiyに通知する。 // ※ユーザー操作ブロックのためのローディング表示 showProgress.postValue( status is BillingManger.Initializing || status is BillingManger.ReadyToPurchased || status is BillingManger.ReadyToRegister ) }.addTo(compositeDisposable) } // 不要になったら解放 @OnLifecycleEvent(Lifecycle.Event.ON_DESTROY) fun onDestroy() { billingManager.release() compositeDisposable.clear() } BillingActivity
このクラスはUI操作をViewModelに伝えることと、状態に応じたUI操作を担当しています。処理の流れは以下の通りです。
課金機能の画面で課金ボタンやリストアボタンのタップをトリガーに、Activityが起動する。 GooglePlay課金の準備が完了したら、BillingActivity自身を渡して課金処理を開始する 課金処理が終了するまでBillingViewModelのステータス更新を監視し、状況に応じてUIの更新を行う。 // 1. 課金機能の画面で課金ボタンやリストアボタンをタップをトリガーに、Activityが起動する。 override fun onCreate(savedInstanceState: Bundle?) { super.onCreate(savedInstanceState) // 2. GooglePlay課金の準備が完了したら、自分自身を渡して課金処理を開始する viewModel.startPurchase.observe(this) { viewModel.onSubscribe(this, it) } // 3. 課金処理が終了するまでViewModelのステータス更新を監視し、状況に応じてUIの更新を行う。 // ローディング表示 viewModel.showProgress.observe(this) { if (it) { binding.progress.toVisible() } else { binding.progress.toGone() } } // プレミアムユーザー昇格の通知 viewModel.purchaseRegistered.observe(this) { Snackbar.make(binding.root, it, Snackbar.LENGTH_LONG) .show() } } 抜粋した内容となりますが、以上のように、3つのクラスに分けて責務を分離し、それぞれの役割を明確にすることで、見通しの良いコードになるようにリファクタリングを進めました。大規模なリファクタリングとなったため、アップデート後の不具合が懸念されましたが、アップデート以降課金に関係したトラブルは発生せず、数ヶ月が経過したので安心しています。
※もちろん事前に全ての課金機能の動作確認は実施しています。
おわりに 今回はライブラリアップデートのきっかけに、課金機能のリファクタリングを行なった事例をお伝えいたしました。前回までに紹介したリファクタリングの方針が、課金機能のリファクタリング後に決まったので、一部既存の理想系と外れる部分もありますが、今後も継続的に改善を進めていく予定です。最後までお読みいただきありがとうございました!
PR コネヒトでは、バリバリとリファクタリングを進めてくれるAndroidエンジニアを募集中です!
hrmos.co
「こんなところも?」 CakePHP4・phpunitのアップグレードに伴う変更箇所
コネヒト
2022-03-01 09:47:40
こんにちは!
Webエンジニアをやっている西中と言います。
弊社では開発組織として運用しているサービスのフレームワークのアップグレード対応を定期的に行っています。
今回は私がCakePHP4.3対応をしていった中で躓いたポイントをいくつかピックアップしていきたいと思います。
CakePHP4.3にアップグレードするにあたって、phpunitのバージョンも8.0にアップグレードしました。
CakePHP4自体のアップグレード対応は一括で対応できるものが割と多い印象で、個人的にはphpunit周りの変更の方がインパクトが大きいのではないか…?と思っています。
assertArraySubsetが廃止!! Deprecate assertArraySubset() · Issue #3494 · sebastianbergmann/phpunit 正に衝撃! phpunit8で廃止、phpunit9で削除! 良い感じに2つの配列を比較してくれるこのAssertion。 同じ機能が欲しいなら拡張機能として作れ(使え)ということですが、 どういう値を比較してどういう状態であるべき か、テストケースを見直す良い機会と捉えてテストケースを見直しました。
Fixtureの責務の分離 CakePHP4.3以降ではFixtureからスキーマ定義の責務が分離されました。 今まではFixtureファイルの中にテーブルの列定義を宣言する必要があったため、テーブルの変更とともにFixtureファイル内の列定義も更新する必要がありました。
CakePHP4.3以降ではFixtureの責務は「テストデータの定義」のみとなり、CakePHPのMigration機能を利用しているのであれば、そのまま反映させることが出来るようになりました。
また、SQLのダンプファイルを元にテスト用のスキーマを作成するという方法も取ることが出来るので、より柔軟に開発ができるようになっています。
弊社ではスキーマの定義をアプリケーション外で管理しているため(参照:AWS × slackを用いたDDL自動実行フローを構築しました - コネヒト開発者ブログ)、今回はDDLファイルをテスト実行時に読み込むというやり方を取っています。
アップグレードマニュアルにあるように、DDLファイルを読み込むだけでOKなので運用・管理のコストはそこまで高くありません。
// in tests/bootstrap.php use Cake\TestSuite\Fixture\SchemaLoader; // Load one or more SQL files. (new SchemaLoader())->loadSqlFiles('path/to/schema.sql', 'test'); Test内のRoutingが効かない? CakePHP4.x系はテスト時にRoutingが自動的に読み込まれないので、 Testクラスの setUp メソッドなどでRouting設定を読み込む必要があります。
cakephp - MissingRouteException in test of Table Object - Stack Overflow public function setUp(): void { parent::setUp(); // Routingの初期化 $this->loadRoutes(); } 今回はちょっと見落としがちな3つの変更点を紹介させていただきました。
他の弊社メンバーの投稿にもCakePHP4へのアップグレードに関する記事があります。 今後もCakePHP4系へのアップグレードに関する記事が投稿されると思うので、同じように悩まれている方の参考になれたらとても嬉しいです。
CakePHP3から4へのバージョンアップ時に困ったキャッシュ周りの話 - コネヒト開発者ブログ
Webpack5 にバージョンアップしました。
コネヒト
2022-02-16 07:31:19
こんにちは! フロントエンドエンジニアの もりや です。 今回はママリのアプリ内で使われている WebView の Webpack を v4 から v5 にアップデートしたので、その事例を紹介します。
Webpack5 は2020年10月にリリースされたので、特に目新しい情報はありませんが、1つの事例として読んでいただければ幸いです。
はじめに 今回のアップデートは、以下2つの公式ドキュメントを参考に進めました。
To v5 from v4 | webpack Webpack 公式の v4 から v5 へのマイグレーションガイド Webpack 5 release (2020-10-10) | webpack Webpack v5 のリリース情報 リリース情報を見たところ、Webpack5 で破壊的な変更はなく、Webpack4 系の最新で非推奨のメッセージが出ていなければアップデートできるようです。 実際にやってみたところ、Webpack 本体は割と簡単にアップデートできました。
ただし、プラグインやローダーのアップデートでちょっと手間がかかりましたので、そのあたりを中心に紹介します。
アップデートの流れ Webpack4 と webpack-cli を最新に上げる プラグイン、ローダーを可能な限り最新に上げる Webpack5 にアップデート プラグイン、ローダーを最新に上げる 動作確認 1. Webpack4 と webpack-cli を最新に上げる まず Webpack を v4 系の最新にアップデートします。 2022-02-01 時点で最新は以下のようになっていました。
webpack: v4.46.0 webpack-cli: v4.9.2 この時点で非推奨のメッセージが出たり、非推奨のオプション を使っていなければOKです。 出ている場合は、それぞれ内容に応じて修正をします。
コネヒトの場合、アップデートによって非推奨のメッセージが出たり、非推奨のオプションを使用している箇所はありませんでした。
2. プラグイン、ローダーを可能な限り最新に上げる Webpack で使用しているプラグインやローダーがある場合は、可能な限り最新にアップデートします。 「可能な限り」と書いたのは、最新バージョンだと Webpack4 では使えない場合があるためです。
コネヒトの場合、2つのプラグインで引っかかりました。
まず mini-css-extract-plugin というプラグインの場合、v2 系は Webpack5 のみのサポート になったので、この段階では v1 系の最新にアップデートしました。
また optimize-css-assets-webpack-plugin というプラグインの場合、Webpack5 では css-minimizer-webpack-plugin を使うようにと書かれていたので、この時点では変更を控え、Webpack5 にアップデート後にライブラリを差し替えました。
このようにライブラリによって、それぞれのライブラリのドキュメントを見て判断する必要があります。 ただ数も多いので、ライブラリを一つずつバージョンアップしてビルドが通るかどうかを見て、エラーが出た場合はドキュメントなどを確認する、という感じで進めました。
3. Webpack5 にアップデート いよいよ Webpack5 にアップデートします。
コネヒトの場合、アップデートしてみるとビルドエラーが出ました。 ただエラーメッセージを見たところプラグイン関連のエラーだったので、次のプラグイン、ローダーを最新に上げる対応に進みました。
4. プラグイン、ローダーを最新に上げる 2. で Webpack5 でないと使えなかったプラグインやローダーの最新版にアップデートしました。
mini-css-extract-plugin → 最新バージョンに上げる optimize-css-assets-webpack-plugin → css-minimizer-webpack-plugin に差し替え css-minimizer-webpack-plugin の README に従って導入すれば特に問題なくできました。 5. 動作確認 正常に動作し、CIでのテストなどチェックが完了したら、最後に実機で動作テストします。
コネヒトの場合、この段階では特に問題は出ませんでした。
余談ですが、以前 「ママリの WebView を JavaScript + Flow から TypeScript に移行しました - コネヒト開発者ブログ」 の際に Cypress によるスクリーンショットの比較テストを導入していたので、明らかに動作しない場合などは作業途中でも自動で検出できました。 特定のページだけライブラリの関係で表示されないケースもあり、コミットしてプッシュするたびに自動でチェックしてくれるので効率が良かったです。
おわりに 既に Webpack5 がリリースされて1年以上経っているためか、関連ライブラリ含めドキュメントが充実していたので、比較的簡単にアップデートができました。
また自動テストを整備したおかげで効率よく作業を進められ、テストの重要性も感じました。
今後もママリのモダン化を進めていきたいです。
PR コネヒトでは、フロントエンド開発のモダン化に挑戦したいエンジニアも募集中です!
hrmos.co

APIクライアントをAPIKit+RxSwiftからURLSession+Combineにしました(後編)
コネヒト
2022-02-15 07:07:54
コネヒト株式会社でiOSエンジニアをやっています ohayoukenchan です。
APIクライアントをAPIKit+RxSwiftからURLSession+Combineにしたお話の後編にあたります。
前回までのお話はこちらをご参照ください。
APIクライアントをAPIKit+RxSwiftからURLSession+Combineにしました(前編) APIクライアントをAPIKit+RxSwiftからURLSession+Combineにしました(中編) 今回は中編で定義したprotocol ApiServiceに準拠したテストを書いていきます。 前提としてNimble, Quickを使ってユニットテストを行っているのでNimble, Quickを使ったテストの書き方になっていますのでご了承ください。
おさらい まずはApiServiceがどんなProtocolだったかおさらいしておきます。
protocol ApiService { func call<Request>(from request: Request) -> AnyPublisher<Request.Response, APIServiceError> where Request: APIRequestType } ApiServiceはAPIRequestTypeに準拠した型を引数にもつcall(from Request)という関数が、返り値としてAnyPublisher<Request.Response, APIServiceError>を返すことを制約としていました。 APIRequestTypeについては 前編を参考にしてください。
APIと通信する際はエンドポイント毎にAPIRequestTypeに準拠した構造体を用意し、実装したApiServiceのcall(from:)にてURLRequestを作成してdataTaskPublisher(for: urlRequest)を叩くことでレスポンスを受け取っていました。テストを書く際もこのプロトコルに準拠させることで可読性の高いテストを書いていきたいと思います。
HTTPリクエストのテスト まずHTTPリクエストのテストについて考えます。
リクエストの成功、失敗 HTTPリクエスト自体をテストしたいケースとしては以下のようなものが考えられます。
HTTPリクエストがなんらかの理由で失敗した場合、レスポンスとして返ってきた情報を正しく操作できているか確認したい。 HTTPリクエストが成功した場合、パース処理にdataが渡っていることを確認したい。 パース処理の確認 正常にレスポンスが渡ってきた場合でも、パースに失敗した場合クライアント側にデータを渡す訳にはいかないので、こちらも正しくエラーハンドリングできているか確認したいので、パース結果が適切かもテストしていきたいと思います。
どのようにテストを書きたいか どんなテストが書きたいかを再確認したところで、どのように書きたいかを考えていきます。 当初自分の頭の中にあったイメージはこのようなものでした。
シナリオ
レスポンス対象となるjson文字列を作成 リクエストを作成 作成したデータをアダプターみたいなもので注入 注入したデータがパースされていてテストが通る もう少し具体的にコードを交えて書くとこのような感じです。
describe("AppleAttach") { it("AppleID連携できる") { let data = try? JSONSerialization.data( withJSONObject: [ "user_linked_accounts": [ "apple": true, ] ], options: [] ) // 1. json文字列に変換 let request = UserLinkedAccountsAttachRequest.AppleAttach( authorizationCode: "123" ) // 2. リクエスト作成 3. 作成したデータをアダプターみたいなもので注入 // apiService.adapter = dataみたいな感じ waitUntil(timeout: .milliseconds(100)) { done in apiService.call(from: request) .sink { completion in switch completion { case .finished: break case .failure(_): fail() } } receiveValue: { response in expect(response.userLinkedAccounts.apple).to(beTrue()) done() } .store(in: &cancellables) } // 4. 注入したデータがパースされてuserLinkedAccountsになっていてテストが通る } } 3の作成したデータをアダプターみたいなもので注入をどのように実現するのかイマイチよく分かっていなかったのでどうしようかなと調べていたら、URLProtocolを使用して、サーバーの応答を直接モックすることができることが分かりURLProtocolにモックする方法で書くことにしました。
URLProtocolとは Appleのリファレンスには
An abstract class that handles the loading of protocol-specific URL data.
プロトコル固有のURLデータのロードを処理する抽象クラスとあります。
abstract class? それならprotocolでいいのでは?と思いつつマニュアルどおりにmockURLProtocolを実装するとこのような感じになりました。詳しくは wwdc2018 | Testing Tips & Tricks をご確認ください。ほぼ同じ実装です。
class MockURLProtocol: URLProtocol { static var requestHandler: ((URLRequest) throws -> (HTTPURLResponse, Data?))? override class func canInit(with request: URLRequest) -> Bool { return true } override class func canonicalRequest(for request: URLRequest) -> URLRequest { return request } override func startLoading() { guard let handler = MockURLProtocol.requestHandler else { assertionFailure("Received unexpected request with no handler set") return } do { let (response, data) = try handler(request) guard let data = data else { assertionFailure("Unexpected Null value given") return } client?.urlProtocol(self, didReceive: response, cacheStoragePolicy: .notAllowed) client?.urlProtocol(self, didLoad: data) client?.urlProtocolDidFinishLoading(self) } catch { client?.urlProtocol(self, didFailWithError: error) } } override func stopLoading() { // 何もしないが上書きする必要がある } } requestHandler は、後でカスタムサーバーの応答を渡します。
下記4つの関数はoverrideする必要があります
canInit(with request: URLRequest) -> Bool canonicalRequest(for request: URLRequest) -> URLRequest stopLoading() startLoading() MockURLProtocolを指定したURLSessionを作成する MockURLProtocolを使うためにURLProtocolを指定する必要があるので実装を追加していきます。
final class MockAPIService { var urlSession: URLSession init() { let configuration = URLSessionConfiguration.ephemeral configuration.protocolClasses = [MockURLProtocol.self] urlSession = URLSession(configuration: configuration) } } URLSessionConfiguration.ephemeralはキャッシュ、Cookie、またはクレデンシャルに永続ストレージを使用しないセッション構成となります。標準は.default これで、URLsessionにMockURLProtocolを指定してMockURLProtocolを使用する準備が出来ました。
requestHandlerを使ったデータ注入 MockURLProtocolに定義したrequestHandlerを使ってMockURLProtocolにダミーデータを送る準備をしていきます。 まず、MockURLProtocolにデータを注入できることをprotocolを使って表現します。 ここが自分が分かっていなかった3のデータの注入の部分です。
protocol DataInjectable { var urlSession: URLSession { get } func injectingToMockURLProtocol(using data: Data?) } URLSession型のurlSessionというオブジェクトとinjectingToMockURLProtocol(data:)という関数を持つprotocolを定義しました。 続いてinjectingMockURLProtocolをextensionを使って標準実装します。
extension DataInjectable { func injectingToMockURLProtocol(using data: Data?) { MockURLProtocol.requestHandler = { request in return (HTTPURLResponse(), data) } } } injectingToMockURLProtocol(data:)は外からデータを受け取ってMockURLProtocol.requestHandlerにデータを渡す仕事を目的とします。 これでDataInjectableの実装が終わったので、MockAPIServiceをDataInjectableに準拠させます。
こうなりました。
final class MockAPIService: DataInjectable { var urlSession: URLSession init() { let configuration = URLSessionConfiguration.ephemeral configuration.protocolClasses = [MockURLProtocol.self] urlSession = URLSession(configuration: configuration) } } 標準実装しているのでただ準拠させているだけです。ただこのままだとMockAPIServiceはリクエストできないのでprotocol ApiServiceにも準拠させます。
final class MockAPIService: ApiService, DataInjectable { var urlSession: URLSession init() { let configuration = URLSessionConfiguration.ephemeral configuration.protocolClasses = [MockURLProtocol.self] urlSession = URLSession(configuration: configuration) } func call<Request>(from request: Request) -> AnyPublisher<Request.Response, APIServiceError> where Request: APIRequestType { // なにかかく } } このままだとfunc call<Request>(from request: Request)の返り値がないので中身を実装していきます。といっても中編で定義した処理内容とほとんどかわりません。
let request: URLRequest = request.buildRequest() let decorder = JSONDecoder() decorder.dateDecodingStrategy = .iso8601 decorder.keyDecodingStrategy = .convertFromSnakeCase return urlSession.dataTaskPublisher(for: request) .tryMap { (data, response) -> Data in if let urlResponse = response as? HTTPURLResponse { switch urlResponse.statusCode { case 200..<300: return data default: throw try decorder.decode(ApiErrorResponse.self, from: data) } } return data } .mapError { error in APIServiceError.responseError(error) } .flatMap { Just($0) .decode(type: Request.Response.self, decoder: decorder) .mapError { error in return APIServiceError.parseError(error) } } .eraseToAnyPublisher() これでURLProtocolにデータを注入したテストがかけるようになりました。 テストの全体的な流れはこのようになります。
class UserLinkedAccountsAttachRequestSpec: QuickSpec { override func spec() { let apiService = MockAPIService() var cancellables: [AnyCancellable] = [] beforeSuite { Nimble.AsyncDefaults.timeout = TestConstants.timeout Nimble.AsyncDefaults.pollInterval = TestConstants.pollInterval } beforeEach { cancellables = [] } describe("AppleAttach") { it("AppleID連携できる") { let data = try? JSONSerialization.data( withJSONObject: [ "user_linked_accounts": [ "au": false, "apple": true, "google": false, ] ], options: [] ) // 1. json文字列に変換 let request = UserLinkedAccountsAttachRequest.AppleAttach( authorizationCode: "123" ) // 2. リクエスト作成 apiService.injectingToMockURLProtocol(using: data) // 3. 作成したデータをアダプターみたいなもので注入 waitUntil(timeout: .milliseconds(100)) { done in apiService.call(from: request) .sink { completion in switch completion { case .finished: break case .failure(_): fail() } } receiveValue: { response in expect(response.userLinkedAccounts.apple).to(beTrue()) done() } .store(in: &cancellables) } // 4. 注入したデータがパースされてuserLinkedAccountsになっていてテストが通る } } } } HTTPリクエストのテストはこれでうまく行きそうです。
ViewModelのテスト ViewModelのテストも先程実装したMockAPIServiceでいけるかなと自問自答したときに、ViewModelの関心はAPIの処理が適切にハンドリングされていることではないはずで、URLProtocolを使ってモックするやりかたではないなと思いました。
そのため、MockAPIServiceとは別のサービスクラスを用意しました。先程のサービスクラスはDataInjectableMockAPIServiceに改名しました。
ViewModelのテストシナリオ テストシナリオを満たす前にMVVMパターンのこれらを満たしている必要があります
初期化時にViewModelにAPIを渡すことができる(Dependency Injection) ViewModelの外から渡された値を元にプロパティを変更できる(ViewModelのInput) ViewModelの外から監視しているプロパティが内部ロジックを経て購読できる(ViewModelのOutput) 以上を踏まえた上で今回のケースではAppleIDとの連携について考えたいと思います。
このようなアカウントの連携画面があって、AppleIDがすでに連携済みである場合、ViewModel内のisAppleLoggedInResultというプロパティがtrueになっていることをテストしていきます。 シナリオはこのような感じです
ViewModelを初期化するタイミングでisAppleLoggedInResultはtrueになっている これをテストしていきます。
通信の結果を置き換える 前述の通りViewModelのテストはAPIの通信結果のハンドリングには関心を持たせたくないので通信結果を準備したデータに置き換えていきます。 実際に通信するわけではなく通信結果の代わりにMockAPIServiceに置き換えたデータを渡してそれを返してあげれば良さそうです。
MockAPIServiceにstub(type: Request.Type, response: @escaping ((Request) -> AnyPublisher<Request.Response, APIServiceError>)) where Request: APIRequestTypeを定義してArrayに追加できるようにします。ここではAnyPublisher<Request.Response, APIServiceError>なAnyPublisherが追加される想定です。
final class MockAPIService: ApiService { var stubs: [Any] = [] func stub<Request>( for type: Request.Type, response: @escaping ((Request) -> AnyPublisher<Request.Response, APIServiceError>) ) where Request: APIRequestType { stubs.append(response) } } ApiServiceはcall(from Request)を実装しなければいけないので追加します。
final class MockAPIService: ApiService { var stubs: [Any] = [] func stub<Request>( for type: Request.Type, response: @escaping ((Request) -> AnyPublisher<Request.Response, APIServiceError>) ) where Request: APIRequestType { stubs.append(response) } func call<Request>(from request: Request) -> AnyPublisher<Request.Response, APIServiceError> where Request: APIRequestType { // ここになにかかく } } このMockAPIServiceがcall(request:)されたときに追加したstubがAnyPublisher<Request.Response, APIServiceError>で返ってくるようにcall(request:)の中身を実装していきます。 最終的には下記のようになりました。
final class MockAPIService: ApiService { var stubs: [Any] = [] func stub<Request>( for type: Request.Type, response: @escaping ((Request) -> AnyPublisher<Request.Response, APIServiceError>) ) where Request: APIRequestType { stubs.append(response) } func call<Request>(from request: Request) -> AnyPublisher<Request.Response, APIServiceError> where Request: APIRequestType { let response = stubs.compactMap { stub -> AnyPublisher<Request.Response, APIServiceError>? in let stub = stub as? ((Request) -> AnyPublisher<Request.Response, APIServiceError>) return stub?(request) } .last return response ?? Empty<Request.Response, APIServiceError>() .eraseToAnyPublisher() } // Arrayに登録されている最後のデータを返す。もしくは空のPublisherを返す } MockAPIServiceを利用する 最終的にテストケースはこのようになりました。
final class ProviderLoginSettingViewModelSpec: QuickSpec { override func spec() { var apiService = MockAPIService() var cancellables: [AnyCancellable] = [] // outputs var isAppleLoggedInResult: [Bool] = [] beforeEach { apiService = MockAPIService() cancellables = [] isAppleLoggedInResult = [] } func bindVM(_ vm: ProviderLoginSettingViewModel) { vm.$isAppleLoggedIn .sink { isAppleLoggedInResult.append($0) } .store(in: &cancellables) } describe("init") { context("apple id連携済みのとき") { it("isAppleLoggedInが設定される") { apiService.stub(for: UserLinkedAccountsAttachRequest.Me.self) { _ in Record<UserLinkedAccountsResponse, APIServiceError> { promise in promise.receive( UserLinkedAccountsResponse( userLinkedAccounts: UserLinkedAccounts( au: false, apple: true, google: false ) ) ) } .eraseToAnyPublisher() } // 通信結果を置き換える let vm = ProviderLoginSettingViewModel( referrer: nil, apiService: apiService ) // ViewModelの初期化時にMockAPIServiceをDependency Injectionする bindVM(vm) // viewModelのbinding expect(isAppleLoggedInResult).to(equal([true])) } } } } } expect(isAppleLoggedInResult).to(equal([true])) でUserLinkedAccountsResponseの値に置き換えられていることが分かります。 これでViewModelのテストもうまくかけそうです。
最後に 今回はAPIのテストとViewModelのテストを書く部分についてお伝えしました。 Combine使ってみたいけどテストどうやって書くのかな?とかAPIのテストの書き方など少しでもお役に立てたら幸いです。
URLProtocolのモックやAPIクライアント自作によるURLRequestの生成などで普段エンドポイント作成しているだけでは分からないことが少し分かった気になりました。 余談ですが、初実装ではbodyパラメータの実装がまんま抜けてて、後で気づいて冷や汗を書きました。
ママリはこれからもSwiftUIやCombine含め新たな挑戦をどんどんしていくので、興味を持っていただけたら是非こちらからエントリーいただくか 私までご連絡ください!お待ちしております。
Android版ママリアプリのリファクタ事情 ~ ViewState編 ~
コネヒト
2022-02-07 03:48:46
こんにちは。2017年11月にAndroidエンジニアとしてjoinした@katsutomuです。
昨年のエントリーで緑髪 -> 赤髪 -> 金髪と定期的なアップデートをご報告いたしましたが、今は髪が伸びて、3分の2が黒髪になってきています。
さて今回は、Android版ママリアプリのリファクタリングの事情の第二弾として、ViewState *1 導入提案時のお話を共有します。
導入背景 ママリアプリの実装は、ViewModelにUI要素ごとの状態をLiveDataで持ち、状態管理を行っています。この場合、UI要素が増えるたびにViewModeにLiveDataが増やすことになるため、UIの状態管理の難易度が高い状態になっていました。
この解決策としてViewの状態を1つにまとめたViewStateの導入方針を提案したところ、LiveEventの扱いをどうするか?が主な議題になりました。
なぜLiveEventが必要か?
まず、LiveEventが必要とされている理由についておさらいしておきます。
github.com
ママリアプリではViewModelとViewの間のやりとりの中で、一度だけ実行したいイベントの場合、LiveEventで実装をしています。例えば、以下のようなユースケースです。
メッセージ表示 自動的で消えるトースト表示 操作が伴う入力フォームやエラーダイアログ表示 画面ナビゲーション 質問投稿後の画面移動など この場合LiveDataで実装すると、困ったことがおきえます。LiveDataが常に最新の状態を保持し、Activityがバックグラウンドからフォアグラウンドに戻った場合にも、最新の状態を受け取る性質を持つため、一度きり表示したいメッセージが再び表示される、実行済みの画面ナビゲーションが再実行されるといったことが起きてしまいます。
これらの解決策として、一度だけイベントが送信されることを保証するLiveEventを利用しています。
導入方針の検討 今回はこのLiveEventが必要な事情を考慮に入れ、ViewStateの導入後の設計を2パターン比較して、方針を相談しました。
1. 状態とイベントを区別するパターン
社内で上がってきたアイディアの一つです。ViewModel → Viewに反映するべき状態をViewStateで保持し、一度きりのイベントをViewCommandで伝えます。
pros
UIの状態とイベントで使い分けができる。特に画面ナビゲーションはその方が直感的。 cons
Viewに影響を与える要素が複数になり、複雑度が増す 2. 状態とイベントを一緒に扱うパターン
最近アップデートされた、Googleのアーキテクチャガイドラインでのアプローチです。ViewModel → Viewに反映する状態や画面遷移のトリガーは全てViewStateで持ちます。
pros
Viewに影響を与える要素が一つになり、複雑度が下がる cons
全てをまとめると肥大化しそう。画面ナビゲーションがViewStateに入るのは違和感ある。 ViewModelのonShownを呼び出すなど、ちょっと冗長 FYI:https://developer.android.com/jetpack/guide/ui-layer/events#consuming-trigger-updates 上記の2つのパターンで比較し、Googleのアーキテクチャガイドに従うことや、Viewに影響を与える要素を一つにすることが、今後はメリットが大きいと判断し、状態とイベントを一緒に扱うパターンを選択することにしました。
その後、想定される3つのユースケースの具体的な実装方法をつめて、結果的に以下のルールを選定しました。
1. 自動で消えるメッセージ表示
ViewStateに表示メッセージを持たせる。表示したら表示完了をViewModelに伝える。
2.ユーザーの操作を伴う入力ダイアログやエラーダイアログ表示。
ViewStateに表示メッセージを持たせる。重複表示はUI側で制御し、再表示が不要になったらViewModelに伝える。
3.画面ナビゲーション
ViewStateに入れることが違和感を感じるため、別のイベントとして扱う。
結果的に、Googleのアーキテクチャガイドのパターンをベースにしつつも、現時点では画面ナビゲーションはViewStateと分けて管理する方が、コネヒトのAndroidチームでは違和感が少ないと判断し、このルールを選定しました。今後はこのルールをベースにリファクタリングを進めていく予定です。
参考までに、相談時の議事録を共有しておきます。
議事録メモ
- 自動的に消えるようなトーストメッセージ表示 - ViewStateのみで扱う違和感ない - ユーザーの操作を伴う入力ダイアログやエラーダイアログ表示 - ViewStateのみで扱う場合、少し違和感 - 表示してすぐにonShown呼び出す。 - UI側で表示制御をするのはあり 1. ViewModelから表示したいメッセージを送る - uistateに表示したいメッセージが入る 2. Viewはメッセージを受け取ってダイアログを表示する。 - View側で、多重表示しない制御を入れる 3. ダイアログ非表示 - ユーザーが操作してダイアログを非表示にする - viewModel.onShown() - uiStateから表示したいメッセージ消す - ViewModelから消したいパターン - uiStateから表示したいメッセージ消す - DialogFragment:tagで表示確認した上で表示する。 - AlertDialog:UI側でフラグ管理する?ちょっと冗長。そもそも今回の場合はAlertDialogじゃなく、Toastや入力フォームエラー表示するのがベターかも? - Alert Dialogは単体で使わないほうが良い認識。 - DialogFragmentに内包して使うとリーク問題が解決する。 `そもそもダイアログは本当に必要な場合だけ使うように限定したい` - 画面ナビゲーション - ViewStateの方法だと違和感あるかも。これだけViewCommandで扱うのはあり。 - その場合は名前を変えた方が良さそう - 将来的にはJetpack Navigationで実装したいが・・・。 - ActivityからActivityに切り替えるパターン - ViewCommandの名前をNavigationCommandにしてワンショットでイベントを送る - 1Activityで複数Fragmentを切り替えるパターン - こちらはViewStateにシーンの概念を持たせるのが良さそう 提案前にやっていること 筆者は、新しい設計や機能を試すときに、弊社のGitHub上にAndroidのコードを実験するシンプルな構成のAndroidプロジェクトを用意し、一度実験した上で、提案を進めるようにしています。
せっかくなので、今回のViewState導入の提案前に実験したサンプルコードを抜粋して紹介します。
サンプルコード
// 画面全体のUIの状態を表したクラス。 data class MamariUiState ( val contents: List<ListViewItem> = listOf(), val errorMessage: List<ErrorMessage> = listOf() ) class MamariViewModel: ViewModel() { // メッセージの内容をViewStateで private val _viewState = MutableStateFlow(MamariUiState( errorMessage = listOf( ErrorMessage( UUID.randomUUID().mostSignificantBits, "errorだよ" ) ) )) val viewState = _viewState.asStateFlow() // 表示されたらメッセージを破棄する。 fun onErrorShown(errorId: Long) { _viewState.update { current -> val newErrorMessage = current.errorMessage.filterNot { it.id == errorId } current.copy( errorMessage = newErrorMessage ) } } } 終わりに 今回はリファクタリングの2歩目を紹介いたしました。最終的なアーキテクチャは過去の記事で触れていますので、是非そちらもご一読ください!
tech.connehito.com
PR コネヒトでは、バリバリとリファクタリングを進めてくれるAndroidエンジニアを募集中です!
hrmos.co
*1:UIStateと呼ばれることも多いですが、弊社ではViewModelと近しい存在と捉えて名前も寄せています

リモートワーク下でのデイリースクラム運営tips
コネヒト
2022-01-25 06:00:00
こんにちは! @takoba_ です。
最近は ダウ90000 という8人組の演劇・コントユニットにハマっています。ホント大変だったよ〜〜*1
リモートワークでのプロダクト開発、難易度上がってない?? アジャイル開発における(現時点での)筆頭とも言えるフレームワークである「 スクラム(Scrum) 」ですが、わざわざ “筆頭” と呼ぶくらいに多くのプロダクト開発現場で導入されている手法になりつつあります。
一方で、直近のスクラムに関するアップデートといえば、 2020年に原典となるスクラムガイドが改訂される というイベントはあったものの、世界的に発生している 新型コロナウィルス(COVID-19)感染症のパンデミック によってリモートワークが新常識となった2022年現在において、リモートワークを前提としたスクラムに関連する模索が各所のプロダクト開発現場で続いているものだと思われます。
一般的に、リモートワークへの移行によって同期的なコミュニケーション(ここでは会話などを指す)が自然と減ってしまうことにより、スピード感の欠如や共通認識の齟齬が発生するなどの影響が発生しているものと思われます。*2
要は、スクラムを採用している如何に関わらず、 リモートワークに移行したことで全体的にプロダクト開発という仕事の難易度は上がっている と思われます。
ちょっとでもスクラムで円滑なプロダクト開発に貢献したいぞ なので、上記のような状況を踏まえつつも、スクラムを採用することでコミュニケーションロスが減ってプロダクト開発が円滑になればな〜〜〜と個人的には思っていたりします。(実はそんなに問題視していない成熟したスクラムチームもあるかもしれませんが)
というわけで、今回はコネヒト社の @takoba_ が所属するチームにおいて、リモートワークに移行したことで発生した、スクラムの各種機能に関する工夫をお届けしようかな!と思い立って、筆をとった次第でございます。
[PR] コネヒト社でのリモートワークに関する発信まとめ ちなみに、過去に @dachi_023 が書いたリモートワークに関するエントリがあるので、こちらもよかったらご覧ください〜〜
tech.connehito.com
tech.connehito.com
リモートワーク下におけるデイリースクラムの運営tips 今回は、デイリースクラムがどのように変化したか、をお伝えできればよいかな!と思います。それでは行ってみましょ〜〜〜🙋♀️
基本、司会の人がディスプレイを画面共有する だいたいカンバン(弊チームだと ZenHub 使ってます)を開いて、画面を共有しておきます。
まあ、司会者の手元を共有してなくても ZenHub とか GitHub Project とかだったら URL さえ共有しておけば同じものが同期的に見れるんですが、 Zoom などで画面を共有することは「(同じものを見てるぞ!という感覚で) Zoom に参加しているメンバーのマインドシェアをジャックする」的な感覚が発生してそうで、画面共有することを薦めてます。まあ注視させるというかなんというか。このあと話す ”デイリースクラムでのメモを残す” ことでも話しますが、ホワイトボードの前にみんなが集まる、みたいなイメージを残したい意図もあります。
式次第のメモを書いておいて、それの通りに進めて、やる人によるブレを減らしておく 司会の人の進行力によって、デイリースクラムの品質が下がらないように、進行台本(個人的には式次第と呼んでる)を用意して、それをベースに進行するようにしています。
ここでは、特に公開しても問題なさそうだったので、弊チームで用いている式次第を公開します。
Slack 上にメモを書く準備 いまのところ Slack 上にブロードキャストするようにしてるので、直接 Slack に書いてる カンバン見ながら各開発者から1-2分程度で共有 前回のデイリースクラムからやったこと このあとやろうとしてること 困ってることとか相談とか スプリントゴールの達成度合いを確認 もし、今回のスプリントで達成できなさそうなゴールがあれば、スコープの調整/差し戻しを行う スプリントゴールのいけそう感を各開発者に尋ねたりする 前回のスプリントレトロスペクティブで決めた Try の進捗を確認する Try は各人にアサインされてたりする(必要に応じて issue を切るけど、あえて緩めに管理してる) 休暇をとってるメンバーがいたら、その人へのフォローを行う お休みのメンバーにアサインされてる issue があれば、状況を整理してアサインし直す できるかぎりアサインされてる issue がない状態でお休みをとってもらいたいけど、そうじゃない場合もあるから 最後にその他の連絡/共有を聞く 直近のお休み予定とか mtg の時間調整とか 何か告知事項 スプリントの最終日に近づいてきたら、スプリントレビューでデモするスプリントゴールを選んだりする Slack でチームのチャンネルを開いておいて、メモをとる これは、現時点では @takoba_ が推し進めてて式次第にはガッツリ入れてないんですが*3、なんとなくデイリースクラムのサマリーを残しておいた方が、状況や雰囲気が Slack のチャンネルを通してチームメンバーやその他不特定多数に伝わる気がしてて、やってます。
また、リアルタイムにメモを書き始めると「あれ?これってどうなってたっけ?」「あっ、このタスク漏れてないすか??」みたいな疑問が自然と現れてくるんですよね...なんでなのかわからないんですが、めちゃ便利です。
コミュニケーション構造としてホワイトボードが寄与していたもの こういうオフラインのディスカッションが懐かしいわね...( ˘ω˘)
んーこれなんでなんだろな... Zoom ってオフラインで車座(円形)になってスタンディングしてるのとなんか違う気がしていて、コミュニケーションが P2P みたいな1対1の構造になってて、情報が情報が内にとどまってしまうというか、外化されにくい気がします。
なので、ホワイトボードに書き出すが如く、 Slack の投稿画面を見せながらメモを書くことで、 ホワイトボード(=外化された情報)を見ながら会話する構造に変化できる 気がします。
なお、この話は科学的根拠はなく、自説に基づいた仮説なんですが、 ワークショップ設計の文脈で「壁に貼られたポストイットを眺めながら(対面せずに)肩を並べて複数人と会話する、みたいな構造にすることで心理的安全性が発生しやすい」みたいな経験則 はあります。ワークショップを運用するときに、そういう会話構造になるような立ち位置を設計することが大事だよ〜〜というかんじです。*4
おわりに とりあえず3つほど紹介しましたが、いかがでしたか?参考になりそうなものはあれば幸いです🙏
新常識となったリモートワークにきっちり順応して、よりよいプロダクト開発に邁進できるようにやっていき!💪
参考 スクラム (ソフトウェア開発) - Wikipedia) スクラムガイド2020のアップデートについて - Scrum Inc. Japan #TeamworkMakesTheDreamWork 毎朝15分以上のデイリースクラムをしてる - Mitsuyuki.Shiiba 問題 vs 私たち - Google 検索 社内向けにまとめていたリモートワークの知見をすべて公開します - コネヒト開発者ブログ *1: ダウ90000 のコント「バーカウンター」より
*2:特に根拠となる論説はないのですが、肌感として
*3:お休みの人がいたら必ず書くようにはしてるけど
*4:これ当時アイエムジェイ(現アクセンチュア)に在籍されていた太田文明さんに指摘されて「なるほど確かに〜〜〜」となった話だったんだけど、 @fortkle に「これ"問題 vs 私たち"の構図だよね〜」って教えてもらってスッキリしました!ありがと〜〜
Tableauのパラメーターを横並びのラジオボタンにする拡張機能をつくった
コネヒト
2021-12-24 01:00:00
こんにちは!コネヒトのエンジニアあぼです。この記事はコネヒト Advent Calendar 2021の24日目です。
今回は、コネヒトでデータ分析や新規プロダクトに使われているTableauの拡張機能をつくったので紹介します。
つくったもの github.com
この拡張機能は、ダッシュボード上から参照できるパラメーターを1つ、横並びのラジオボタンとして表示するシンプルな拡張です。
「構成」からダイアログを開くと、ダッシュボードから参照できるパラメーターのうち許容値がリストであるものが表示されるので、この中から横並びのラジオボタンにしたいパラメーターを選択します。すると、パラメーターを画像のように横並びで表示することができます。
ちなみにダッシュボード上に拡張機能オブジェクトを複数設置すれば、複数のパラメーターにも対応できます。.trexファイルをダウンロードすれば誰でも使えるので、ぜひ使ってみてください! 💪
つくったきっかけ 業務で必要になったのがきっかけです。Tableauでは許容値がリストであるパラメーターはラジオボタンのようなUI(単一の値のリスト)で表示することができますが、横並びにするような設定がありません。
許容値がリストであるパラメーター。この場合Order ID, Order Date, Customer Nameの3種類の文字列を取りうる。
ダッシュボードのスペースやUI設計の都合上、横並びにしたかったため方法を探していました。Tableauコミュニティでも同様の相談が複数見受けられました。できないからといってクリティカルではないものの、どうにかできないかな〜と考えていました。
こういった公式がまだ機能として提供していないものについては、Tableauのコミュニティでtipsが共有されたりしています。今回のラジオボタンの横並びについてもコミュニティでtipsを見つけることができました。具体的にはこちらのYouTubeの動画や、こちらのナレッジベースのように、ワークシートやダッシュボードアクションを駆使することで横並びのラジオボタンをつくることができるというもので、これはこれで素晴らしいのですが、
多少手間がかかる リストの値を取るデータフィールドがないようなデータ構造だとできない という問題がありました。前者はしょうがないとしても、今回のきっかけとなったデータ構造は後者に該当するためこの方法ではできませんでした。後者は例えば動画内で出てきた計算フィールドSTR([Region Parameter] = [Region]) + [Region]において、RegionはRegion Parameterで定義したリスト内の値をとるデータでなければいけません。Region ParamerterがEast, West, Central, Southの4つの文字列を許容値とするリストならば、その4つの文字列を取りうるRegionというデータフィールド(列)が必要ということです。
Tableau付属のデータセット「Superstore」のRegionのようなデータ構造なら可能
そこで、Tableauが提供しているもう一つの選択肢、拡張機能を使うことにしました。ユーザーはTableauのギャラリー(Tableau公認*1)や、ユーザーコミュニティポータルで公開されている拡張機能を探してダッシュボードに組み込めるほか、Tableau Extension APIを活用して自作することもできます。
今回はニーズに合う拡張機能が見つからなかったので自作しました。拡張機能をつくるには、Tableauの知識、Tableau Extension APIの知識、多少のWebアプリケーション開発の知識が必要になります。今回のようなシンプルな拡張機能であれば比較的簡単につくることができました。
以降では、今回の拡張機能をつくるうえで出てきた実装をいくつか紹介します。
実装 Tableau拡張のつくり方の詳細は公式のドキュメントにまとまっていますのでご覧になってみてください。今回JavaScriptのライブラリは、公式サンプルにも登場するjQueryを利用しました。
ダッシュボード内のパラメーターを取得する ダッシュボード内のパラメーターはdashboardContent.dashboard.getParametersAsync()で取得できます。その中から、許容値がリストであるパラメーターに絞り、inputやlabelを作り反映させています。
tableau.extensions.dashboardContent.dashboard.getParametersAsync().then((params) => { params .filter((p) => p.allowableValues.type === tableau.ParameterValueType.List) .forEach((p) => { const hElement = $('<h3>') $('<input />', { type: 'radio', id: p.name, name: 'HorizontalRadioButton', value: p.name, }).appendTo(hElement) $('<label>', { for: p.name, text: p.name, }).appendTo(hElement) $('#parameters').append(hElement) ) }) パラメーターとラジオボタンを同期させる 拡張機能側のラジオボタンを押したらパラメーターの値も変わるようにする部分です。また、Tableauはダッシュボードアクションなどでパラメーターに作用できるので、ダッシュボード側の操作によってパラメーターが変わったことを拡張機能側で検知して自身のラジオボタンに反映させられるように、つまり双方向に同期されるようにします。
拡張機能からパラメーターへの反映はparameter.changeValueAsync()で行い、パラメーターから拡張機能への反映はパラメーターへイベントリスナーを登録して行います。
tableau.extensions.dashboardContent.dashboard.getParametersAsync().then((parameters) => { const selectedParameter = parameters.find((p) => p.name === savedValue) // パラメーターの変更検知 selectedParameter.addEventListener(tableau.TableauEventType.ParameterChanged, onParameterChange) const parameterValuesElement = $('<div id="parameter">') selectedParameter.allowableValues.allowableValues.forEach((dataValue) => { const eachValueElement = $('<div style="display: inline-block">') $('<input />', { type: 'radio', id: dataValue.value, name: selectedParameter.name, value: dataValue.formattedValue, checked: dataValue.value === selectedParameter.currentValue.value, // 拡張機能 => パラメーター へ同期 click: () => selectedParameter.changeValueAsync(dataValue.value), }).appendTo(eachValueElement) $('<label>', { for: dataValue.value, text: dataValue.formattedValue, }).appendTo(eachValueElement) parameterValuesElement.append(eachValueElement) }) $('#parameter').replaceWith(parameterValuesElement) }) // パラメーター => 拡張機能 へ同期 const onParameterChange = (parameterChangeEvent) => { parameterChangeEvent.getParameterAsync().then((p) => { $(`input:radio[value="${p.currentValue.formattedValue}"]`) .prop('checked', true) }) } 設定をワークブックに保存し永続化する 拡張機能の実態はホスティングされたWebサイトなので、ワークブックの再読み込みで初期化されます。Tableauの拡張機能は基本的に構成ダイアログから設定を変更できるように作りますが、その設定を保存するためのコードを書く必要があります。
設定はkey-value形式で保存でき、ワークブック単位で保持されます。構成ダイアログをひらく場合はtableau.extensions.ui.displayDialogAsync()、とじる場合は tableau.extensions.ui.closeDialog() も呼んであげます。どちらも引数にはpayloadを渡せますが、今回は設定の読み込みと書き込みは全てtableau.extensions.settings経由で行いたかったので、payloadは空文字でも問題ありません。*2
// 構成ダイアログをひらく tableau.extensions.ui.displayDialogAsync('config.html', payload) // 設定をセット tableau.extensions.settings.set('key', value) // 構成をワークブックに保存 tableau.extensions.settings.saveAsync().then(() => { // 構成ダイアログをとじる tableau.extensions.ui.closeDialog(value) }) keyを指定してsettings.get()で保存された値を取得できるほか、イベントリスナーの登録によって設定が変更されたことを検知できます。拡張機能や構成ダイアログの初回読み込み時は settings.get()、以降はイベントリスナー経由で値を取得するという使い分けになります。
tableau.extensions.initializeAsync({'configure': configure}).then(() => { // 初回読み込み時はここで保存された値を取得 savedValue = tableau.extensions.settings.get('key') // イベントリスナーを登録しておいて tableau.extensions.settings.addEventListener(tableau.TableauEventType.SettingsChanged, onSettingsChange) }) const onSettingsChange = (settingsEvent) => { // 最新の値を取得 savedValue = settingsEvent.newSettings.key // UIの更新など } checkedのときにinputが表示されない inputがcheckedのときに消えてしまう不具合がありました。下の画像では「Order Date」がcheckedなのですが、ラジオボタンの丸ポチが消えてしまっています。
原因は特定できなかったため、結局CSSを別途当てることにしました。input[type=radio]に対してdisplay:noneを当てて、labelのbefore/afterに対してスタイルを当てて擬似的にラジオボタンのように見せて対応しました。
おわりに 拡張機能を上手く活用すれば、Tableau Extension APIとWebでできることはだいたいできるので、Tableauの可能性が広がりますね。拡張機能は開発するうえでTableauの理解も深まりますし、コミュニティにも貢献できるのでオススメです!
*1:フォームから申請する必要があるみたいです https://tableau.github.io/extensions-api/docs/ux_extension_gallery.html
*2:https://tableau.github.io/extensions-api/docs/trex_configure.html
Facebook広告で広告費用対効果(ROAS)向上を目指す
コネヒト
2021-12-23 03:55:34
こんにちは! @otukutun です。
今回、Facebookで広告費用対効果(ROAS)向上の取り組みをしたのでここで紹介します。
はじめに インターネット広告では、ユーザーの興味を推定し広告配信しますが、その際に費用対効果などは考慮されていません。例えば、ECショップで広告出稿する際に100円の商品を買う人よりも100万円の商品を買う人に配信した方が売り上げとしては大きいわけですが、現状はそのようになっていません。 Facebook広告では、既に出稿している場合に購入金額の情報をFacebook上に送信することで、例のようなECショップでより高い商品を買う人を機械学習で推定し優先的にターゲティングすることが可能になります(詳しい説明はこちらをご覧ください)
例ではECを出しましたがゲームでも同じようなことができます。スマホゲームで有名なニャンコ大戦争ではROAS対応をすることで、広告費用対効果が前月の2.6倍になるなどの大きな成果が出ています。(下記ページより成果情報を引用)
www.facebook.com
Facebook Conversion APIを導入する インターネット広告ではコンバージョンイベントを送ることでコンバージョン率を計測できると思います。Facebook広告ではFacebookピクセルでそれが実現できます。FacebookピクセルだけでもROAS向上の対応はできるのですが、サーバー側で処理したかったので今回はFacebookピクセルのコンバージョンイベントとコンバージョンAPIを両方使って対応しました。
設定準備 まずイベントがROAS向上対応(以降バリューへの最適化とします)の条件を満たしているかを確認します。条件はこちらから確認できます。
コンバージョンイベントは「購入イベント」しかバリューへの最適化をオンにできないので注意してください。
また、両者からイベントを送る場合は、イベントが同一であることをfacebookに認識してもらう必要があります。同一の認定ロジックの詳細はこちらをご覧ください。
今回はFacebookピクセルとコンバージョンAPIから同じevent_nameとevent_idを送ることで認識してもらうようにしました。
Facebookピクセルの設定 購入ボタンを押して購入画面が表示されたタイミングなど任意のタイミングで、以下イベントを発火させます。Conversion APIで実際の値段を送るためにここでは0円でデータを送ります。
サーバーからConversion APIにリクエストを送る まず、グラフAPIエクスプローラから叩いてみるのが簡単に試せるのでオススメです。
developers.facebook.com
上記ページの動画を参考にすると、グラフAPIエクスプローラ上からConversion APIを試しに送れます。その際、test_event_codeを付与することを忘れないでください。そうしないとtestイベントとみなされません。
今回はConversion APIをPHP SDK経由で使うことにしました。各種言語のSDKがあるのでみてみてください。またサービスの利用規約でどのデータを送るかを確認・検討しておくことも重要です。
PHP SDKを使うと以下のように試すことができます。
use FacebookAds\Api; use FacebookAds\Object\ServerSide\CustomData; use FacebookAds\Object\ServerSide\Event; use FacebookAds\Object\ServerSide\EventRequest; use FacebookAds\Object\ServerSide\UserData; Api::init(null, null, 'ACCESS_TOKEN'); $client = new EventRequest('PIXEL_ID'); $userData = new UserData(); $userData ->setEmail('EMAIL') ->setPhone('PHONE_NUMBER') // It is recommended to send Client IP and User Agent for Conversions API Events. ->setClientIpAddress($_SERVER["REMOTE_ADDR"]) ->setClientUserAgent($_SERVER['HTTP_USER_AGENT']); $customData = (new CustomData()) ->setCurrency('JPY') ->setValue(100000); $event = (new Event()) ->setEventName('Purchase') ->setEventId('event_id') // 任意のevent_idを設定する ->setEventTime(time()) ->setUserData($userData) ->setCustomData($customData); $client->setEvents([$event]); // debug時はtest_event_codeを設定する $client->setTestEventCode('TEST_EVENT_CODE'); $client->execute(); こちらで、動かしてみて、test_eventが送信されることに確認できます。また購入情報を0円を送ろうとした場合は、SDK経由だと除外されて不正なリクエストになるので注意してください。(0円の商品を送ることはそもそもないと思いますが念のため)
test_eventの確認
バリューへの最適化をONにする 購入イベントを送るようになってから、任意のタイミングで設定できるようになります。ただし、ある一定条件をクリアしないとバリュー最適化が設定できないため、気をつけてください。実際の設定方法はこちらを参考にしてください。
おわりに いくつか情報が混在していることと実装上のハマりポイントがありましたが、FacebookからSDKが提供されているので開発自体はシンプルにできるかなと思います。この情報が参考になれば幸いです。
APIクライアントをAPIKit+RxSwiftからURLSession+Combineにしました(中編)
コネヒト
2021-12-23 12:33:29
こんにちわ。 iOSエンジニアの ohayoukenchan です。
前編 でURLRequestを作成するところまでお伝えできたので、今回は実際にURLSessionを前回の変更方針にあった非同期処理を適切に処理したいを解決する内容となっています。
URLSessionとは? URLSessionはURLで示されるエンドポイントからデータをダウンロードしたり、エンドポイントにデータをアップロードしたりするためのAPIを提供します。 アプリは、このAPIを使用して、アプリが実行されていないときや、iOSではアプリがサスペンドされている間に、バックグラウンドでダウンロードを実行することもできます。
単純なHTTPの非同期通信を行うにはdataTask(with:completionHandler:)を用いればいいので、dataTask(with:completionHandler:)で書くとこのような感じになります。completionHandler:のclosureで処理されるdata, response, errorはすべてoptionalな値なので実際に利用するときはunwrapする必要があります。
let task = session.dataTask(with: url!) { data, response, error in if let error = error { // エラーが返って来た場合エラーハンドリング return } guard let data = data, let response = response as? HTTPURLResponse else { // dataが取得出来ない場合のハンドリング return } if response.statusCode == 200 { do { let json = try JSONSerialization.jsonObject(with: data, options: JSONSerialization.ReadingOptions.allowFragments) } catch { // デコードに失敗した場合のエラーハンドリング処理 } // 処理... } } task.resume() // taskをsuspended状態からrunning状態にする dataTaskPublisherでcombine publisherを操作していく 今回はURLリクエストの返り値としてAnyPublisher<Request.Response, APIServiceError>のようなcombine publisherが欲しいのですが、 UrlSessionにはdataTaskPublisher(for:)があり、combine publisherを返してくれるので返り値の理想に近いこちらを使用していきます。
詳細はこちらをご確認ください。
Request処理とその結果を返すクラスを作っていきます。まずは、Protocolの定義をしていきます。今回はApiServiceとしました。 whereを使ってRequestに型制約をもたせておくと予期しないRequest型で実装してしまった場合、コンパイルエラーで気づくことができます。
protocol ApiService { func call<Request>(from request: Request) -> AnyPublisher<Request.Response, APIServiceError> where Request: APIRequestType } ApiServivceクラスはレスポンスエラーとデコードに失敗したときのパースエラーがあることを明示しておきます。
enum APIServiceError: Error { case responseError(Error) case parseError(Error) } 次にApiServiceに準拠したApiServiceクラスを実装していきます。 継承されないようにfinal修飾子をつけておくとどこかで継承して利用される心配がなく安心かと思います。
final class ApiService: ApiService { func call<Request>(from request: Request) -> AnyPublisher<Request.Response, APIServiceError> where Request: APIRequestType { let urlRequest: URLRequest = request.buildRequest() // (1) let decorder = JSONDecoder() decorder.dateDecodingStrategy = .iso8601 decorder.keyDecodingStrategy = .convertFromSnakeCase // (2) return URLSession.shared.dataTaskPublisher(for: urlRequest) .tryMap { (data, response) -> Data in if let urlResponse = response as? HTTPURLResponse { switch urlResponse.statusCode { case 200..<300: return data default: throw try decorder.decode(ApiErrorResponse.self, from: data) } } return data } // (3) .mapError { error in APIServiceError.responseError(error) } // (4) .flatMap { Just($0) .decode(type: Request.Response.self, decoder: decorder) .mapError { error in return APIServiceError.parseError(error) } } // (5) .receive(on: DispatchQueue.main) // (6) .eraseToAnyPublisher() } } (1) let urlRequest: URLRequest = request.buildRequest()のところで前回作成したAPIRequestTypeに準拠したStruct型のリクエスト(前回SampleRequestとしたもの)のbuildRequest()を実行してURLRequestをつくります。
(2) dataTaskPublisher(for: urlRequest)の返り値dataをデコードする際の指定で、Date型にするときiso8601形式に、JSON keyがsnakeCaseの場合、structとのmapping ができるようになります。
(3) dataTaskPublisherはURL session data taskをwrapしたpublisherを返すので.map()オペレータを使うことができます。publisherの中身は(data, response)のタプルです。レスポンス結果に応じて処理を振り分けたいので.map()ではなくtryMap()を使用しています。この場合、HttpStatusCodeが200から300までの値の場合リクエストは正常なレスポンスを返したとして後続の処理にdataを返します その他の場合はthrowキーワードでpublisherの処理を失敗させます
(4) mapErrorはtryMap()で処理が失敗した際にthrowキーワードで投げたエラーを別の型に変換します。ここではAPIServiceError.responseError(error)に変換していますが、画面側でAPIを叩いたときに、 URLリクエストの返り値としてAnyPublisher<Request.Response, APIServiceError>のようなcombine publisherを返して欲しいためです。
(5) .flatMapのjust($0)ですがこちらは(data, response)のタプルのうちdataのみを扱うpublisherにしたいのでこのようにしています。そしてCodable(decodable)を使用してデコードしています。デコードに失敗した場合はレスポンスエラーのときと同じようにmapErrorを使ってAPIServiceError.parseError(error)に変換しています。
(6) URL sessionはバックグラウンドで処理されますが、UIの更新はメインスレッドで行いたいため、receive(on: DispatchQueue.main)でメインスレッドで返すように指定しています。
これでAPIServiceを実装が完了したので、いよいよUI側の処理を書いていくことが出来ます。
リクエストをcombine publisherで受け取る UI側の処理はこのように簡潔に書けます。
let apiService = ApiService() apiService.call( from: SampleRequest.List(query: "foo") ) .sink( receiveCompletion: { [weak self] completion in switch completion { case .finished: break case .failure(let error): self?.errorSubject.send(error) } }, receiveValue: { [weak self] result in self?.fooSubject.send(result.bar) } ) .store(in: &cancellables)} ApiServiceに実装したcall(from:)メソッドにリクエストを渡し、.sink(receiveCompletion:, receiveValue:)することでAnyPublisher<Request.Response, APIServiceError>の値を流します。receiveCompletion:ではcompletionが.failureだった場合APIServiceErrorを流してUI側の制御をします。errorSubjectをUI側で購読できるようにして値が流れてきたらUIAlertをだすなどの処理につなげます。値を受け取った場合、receiveValue:で受け取った値をUIに反映させていきます。
Swift5.3からMultiple Trailing Closuresが使えるのでもう少しシュッと書くことができます。
let apiService = ApiService() apiService.call( from: SampleRequest.List(query: "foo") ) .sink { [weak self] completion in switch completion { case .finished: break case .failure(let error): self?.errorSubject.send(error) } } receiveValue: { [weak self] result in self?.fooSubject.send(result.bar) } .store(in: &cancellables)} インデントが浅くなって可読性があがりました!
これでURLSessionを利用してレスポンスをCombineのAnyPublisherで受け取ることができるようになりました。 しかし、APIが正しく動作するのかのテストが書けていません。
ママリではViewModelの初期化時にApiServiceをDIすることでテストを書けるようにしています。 長くなってしまったのでテストについては後編でお伝えできればと思います。( ^ θ ^ )
余談 WWDC2021のMeet async/await in Swift - WWDC21 - Videos - Apple Developerにもありますが、非同期処理をasync/awaitキーワードを使って自然にかけるようになりましたね。 関数にasync throwsつけて、非同期処理が行われる処理にtry awaitをつけることで非同期処理を安全に処理できるようになります。 ママリにも早く適応させて行きたいず!
struct UserRequest { var session = URLSession.shared func load(from url: URL) async throws -> [User] { let (data, response) = try await session.data(from: url) // レスポンスエラーなど何らかの失敗処理 let decoder = JSONDecoder() return try decoder.decode([User].self, from: data) } }